Worktrees — Drei Visualisierungen parallel bauen

Artikel 6 · Serie: Agentic Coding mit Claude Code
v0.5 liefert ein konsolidiertes Parquet, 377 Titel, ein Manifest. Aber kein Bild. Wie stellt man hierarchische Haushaltsdaten visuell dar? Drei plausible Antworten: Treemap, Sunburst, Sankey. Sequenziell bauen heißt: drei Tage warten und am Ende eine Variante akzeptieren, weil man drei Tage reingesteckt hat. Git-Worktrees lösen das anders.
Worktree, Branch oder Stash
Drei Werkzeuge, drei Kontexte. Die Abgrenzung:
- Stash — kurzfristiger Kontextwechsel, nicht wiederholbar. Für „ich muss nur kurz was anderes prüfen".
- Branch + Checkout — sequenzielle Arbeit an Alternativen. Für Bugfixes, Features, normale Iteration.
- Worktree — mehrere Branches gleichzeitig im Dateisystem. Jeder mit eigenem
node_modules, eigenem Dev-Server, eigenem Browsertab.
Worktree lohnt sich, wenn parallele Sichtbarkeit Wert hat. Drei Visualisierungs-Varianten, die nur in dem Moment vergleichbar werden, in dem sie gleichzeitig laufen, sind genau dieser Fall. Für einen Bugfix-Branch, der nach 10 Minuten gemerged wird, ist Worktree Overhead.
Plan-File für das Frontend
Vier Tasks, davon drei parallelisierbar:
Task 1 (sequenziell): web/-Skelett auf main
Vite + React 19 + TypeScript + Tailwind 4 + Vitest
Daten-Loader, gemeinsame Komponenten-Schicht
Task 2a (parallel): frontend/treemap
Task 2b (parallel): frontend/sunburst
Task 2c (parallel): frontend/sankey
je eine Komponente, je ein Smoke-Test
Task 3: visueller Vergleich + Entscheidung
Task 4: Tag v0.6
Das Briefing pro Variante ist minimal: eine Komponente, ein Smoke-Test, die gemeinsame data.ts aus Task 1 als Eingabe. Die drei Subagents bekommen denselben Datensatz und dieselbe Schema-Definition.
Task 1 — Skelett auf main
Erstelle web/-Skelett auf main:
- Vite + React 19 + TypeScript
- Tailwind 4 via @tailwindcss/vite (kein separates Config-File)
- Vitest + @testing-library/react + jsdom
- d3 + d3-sankey
- data.ts: useHaushalt()-Hook lädt /data/haushalt.json und /data/manifest.json
- types.ts passend zu HAUSHALT_SCHEMA aus parser/
- scripts/copy-data.mjs: kopiert parser/output/{haushalt,manifest}.json nach public/data/
- predev + prebuild hooks rufen copy-data.mjs auf
Claude Code legt die Dateien an, npm install läuft, npm run dev startet auf Port 5173. Das Skelett rendert die Titel-Anzahl und das Manifest, aber immer noch keine Visualisierung.
Jedoch hat damit jeder folgenden Worktree dieselbe Datenbasis. data.ts ist die einzige Stelle, die JSON laden und in Hierarchien umwandeln darf. Die Komponenten sind reine Renderer.
Drei Worktrees öffnen
git worktree add ../byhaushalt-treemap -b frontend/treemap
git worktree add ../byhaushalt-sunburst -b frontend/sunburst
git worktree add ../byhaushalt-sankey -b frontend/sankey
Aus diesen drei Befehlen entstehen drei isolierte Verzeichnisse auf der Festplatte, jedes auf seinem eigenen Branch; der Hauptarbeitsbereich in byhaushalt/ bleibt unangetastet. git worktree list zeigt den aktuellen Stand:
/Users/.../byhaushalt [main]
/Users/.../byhaushalt-treemap [frontend/treemap]
/Users/.../byhaushalt-sunburst [frontend/sunburst]
/Users/.../byhaushalt-sankey [frontend/sankey]
In jedem Worktree einmalig npm install mit jeweils eigenen node_modules pro Verzeichnis. Das kostet Plattenplatz, ist aber Voraussetzung dafür, dass drei Dev-Server gleichzeitig laufen können.
cd ../byhaushalt-treemap/web && npm install && npm run dev -- --port 5173
cd ../byhaushalt-sunburst/web && npm install && npm run dev -- --port 5174
cd ../byhaushalt-sankey/web && npm install && npm run dev -- --port 5175
Ab hier laufen drei Terminals parallel. In jedem startet npm run dev auf einem eigenen Port, in jedem öffnet sich ein Browsertab mit demselben Datensatz. Erst in diesem Moment wird Vergleich möglich, nicht aus dem Gedächtnis, sondern direkt nebeneinander.
Drei Visualisierungen, eine Datenbasis
Pro Worktree ein Prompt an Claude Code:
Erstelle eine Treemap-Komponente in web/src/charts/.
Jeder Einzelplan soll ein Rechteck werden, die Fläche entspricht der Ausgabensumme.
Bitte gleich einen einfachen Test dazu.
Erstelle eine Sunburst-Komponente: innen die Einzelpläne, außen die Hauptgruppen.
Einnahmen in rot, Ausgaben in türkis. Test dazu.
Erstelle eine Sankey-Komponente: Einzelpläne als Knoten, Hauptgruppen als Ziele.
Tabellen links und rechts zum Nachschlagen. Test dazu.
Claude Code schreibt pro Worktree die Komponente und den zugehörigen Smoke-Test. npm run test in jedem Worktree: 2 Tests grün.
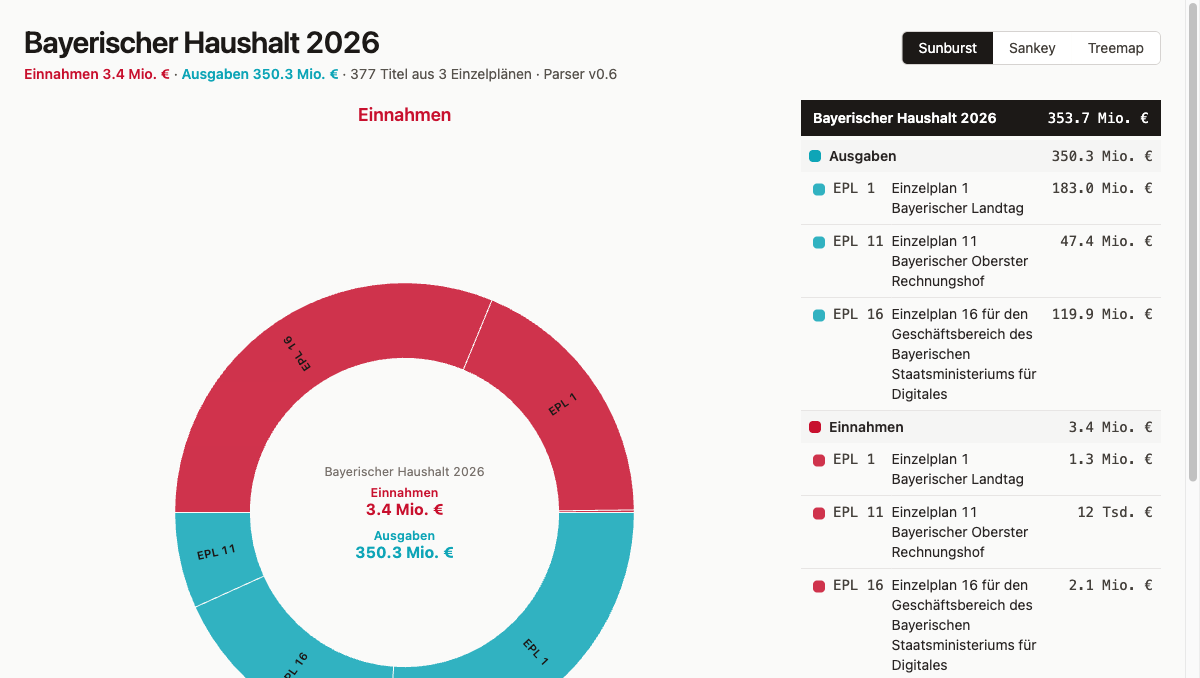
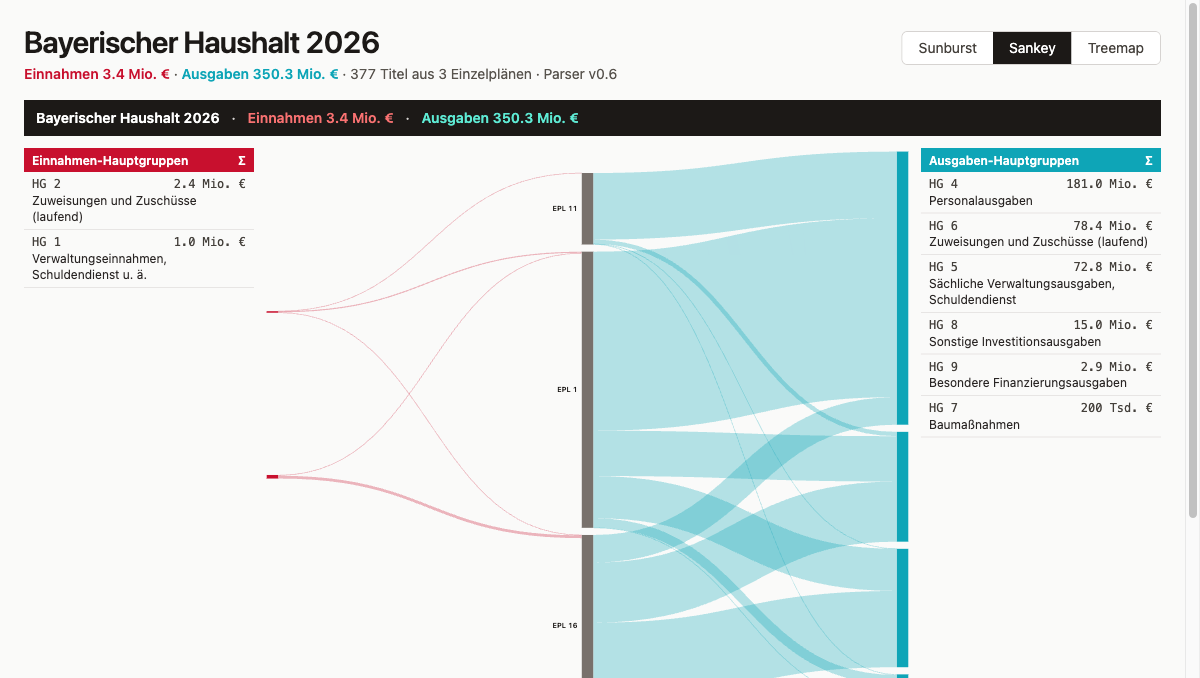
Die Treemap macht Größenverhältnisse sichtbar. Jeder Einzelplan wird zu einem Rechteck, dessen Fläche seiner Ausgabensumme entspricht. Man sieht sofort, welche EPL das Budget dominieren und welche kaum ins Gewicht fallen. Die Sunburst zeigt dieselben Daten hierarchisch: der innere Ring enthält die Einzelpläne, der äußere Ring schlüsselt jede auf ihre Hauptgruppen auf. Hierarchie und Anteile sind gleichzeitig ablesbar. Das Sankey-Diagramm folgt einer anderen Logik: Knoten sind Einzelpläne und Hauptgruppen, Kanten die Geldflüsse zwischen ihnen. Wer verfolgen will, wohin ein bestimmter Einnahme-Typ fließt oder welche Ausgaben-Kategorie aus welchem EPL gespeist wird, folgt einfach den Linien.
In der Vergleichsphase reicht je ein Smoke-Test pro Variante: Vitest mit jsdom rendert das SVG und prüft, ob das data-testid-Element existiert, ob rect- und path-Knoten vorhanden sind. Mehr braucht es nicht. Wer drei Varianten zu früh tiefgehend testet, optimiert eine davon, bevor er weiß, ob sie überhaupt weiterkommt.
Iterationen während des Vergleichs
Die spannenden Entscheidungen kamen nicht aus dem Plan-File. Sie kamen aus dem Browsertab, weil Visualisierungen erst dann wirklich bewertet werden können, wenn man sie sieht. Ein Plan beschreibt, was gebaut werden soll; der Browser zeigt, ob es funktioniert, ob es lesbar ist und ob es die richtige Frage beantwortet. Bei jeder Variante offenbarten sich Probleme, die sich im Voraus nicht vollständig spezifizieren ließen.
EPL-Namen statt Nummern
Als die erste Version im Browsertab läuft, sieht man sofort das Problem: das Label lautet schlicht „EPL 11" und sagt damit nichts. Im PDF steht „Einzelplan 11 Bayerischer Oberster Rechnungshof", doch der Parser hatte bisher nur die Nummer extrahiert, nicht den Namen dahinter. Der Prompt um das zu korrigieren:
Erweitere den Parser so, dass er den Namen des Einzelplans und der Kapitel
aus dem PDF liest und mitspeichert. Der Name steht direkt im PDF-Header.
Zwei Felder in Schema und Dataclass ergänzt (epl_name, kap_name), Parser neu laufen lassen, normalize.py schreibt neue JSON, in allen drei Worktrees git merge main und Daten regenerieren, und schon trägt jeder Einzelplan seinen vollständigen Namen.
Hauptgruppen statt Kapitel
Die erste Drill-Ebene unter jedem EPL war: Kapitel. Im Browser wurde schnell klar, dass das die falsche Abstraktionsebene ist. Kapitel-Namen wie „Landtag" oder „Sammelansätze für den Gesamtbereich des Epl. 11" beschreiben Organisations-Einheiten, keine Inhalts-Kategorien. Die Frage „wofür gibt der Staat Geld aus" bleibt unbeantwortet. Prompt:
Die zweite Ebene soll nicht Kapitel zeigen, sondern nach Ausgabentypen gruppieren —
also Personal, Sachmittel, Investitionen und so weiter.
Das steht als Hauptgruppe im Bundeshaushaltsplan, erste Ziffer der Titelnummer.
Der Unterschied war sofort spürbar. Der Sunburst zeigte jetzt: „Einzelplan 11" → „Personalausgaben", „Sächliche Verwaltung", „Investitionen". Das ist die Information, die jemand sucht, der den Haushalt verstehen will: keine Organigram-Ebene, sondern eine inhaltliche.
Einnahmen UND Ausgaben
Die erste Hierarchie filterte Einnahmen-Hauptgruppen (0–3) komplett aus der Visualisierung raus. Im Browser wurde die Lücke sichtbar: ein Haushaltsplan ist kein reines Ausgaben-Dokument, sondern zeigt er auch, woher das Geld kommt. Beide Seiten gehören in die Visualisierung. Prompt:
Nimm den Filter raus, der nur Ausgaben anzeigt.
Einnahmen und Ausgaben sollen beide sichtbar sein, farblich getrennt.
Summen im Center bitte auch getrennt anzeigen.
Der Sunburst zeigt jetzt in der Mitte beide Totale (Einnahmen + Ausgaben). Bei Klick auf einen EPL-Arc: dessen Einzelsumme. Die Logik dafür ist klein:
const totals = summarizeTotals(titel); // { einnahmen, ausgaben }
// Center-Label rendert beide Werte als Default, EPL-Detail bei Selektion
Sankey: drei Spalten statt zwei
Beim Sankey zeigten sich zwei Iterationen hintereinander, die beide dasselbe Problem hatten. Erst EPL → Kapitel, dann EPL → Hauptgruppe, aber in beiden Fällen wirkte die Flussrichtung beliebig. Geld fließt nicht vom Einzelplan zu einer Hauptgruppe, sondern umgekehrt: Einnahmen-Hauptgruppen speisen den Einzelplan, der Einzelplan speist Ausgaben-Hauptgruppen. Das ist der tatsächliche Zusammenhang, und der ergibt drei Spalten. Prompt:
Ändere Sankey auf drei Spalten: Einnahmen-Arten links, Einzelpläne Mitte,
Ausgaben-Arten rechts. Mit Tabellen links und rechts zum Nachschlagen,
Klick auf eine Zeile hebt den zugehörigen Fluss hervor.
Die finale Anordnung mit Einnahmen-Hauptgruppen links, Einzelplänen in der Mitte und Ausgaben-Hauptgruppen rechts macht den Fluss ablesbar. Flankiert von zwei Tabellen mit Code, Name und Summe, die beim Klick die zugehörigen Flüsse im Sankey hervorheben.
Label-Truncate und Center-Hole
Im letzten Schritt der Vergleichsphase lief der Sunburst selbst noch in ein Layout-Problem: lange EPL-Namen wie „Einzelplan 16 für den Geschäftsbereich des Bayerischen Staatsministeriums für Digitales" liefen einfach aus den Arcs heraus. Die Lösung war pragmatisch: Truncate auf ~22 Zeichen mit Ellipsis, bei zu schmalen Arcs gar kein Label. Gleichzeitig bekam das Center-Loch mehr Platz (INNER_HOLE = RADIUS * 0.33), damit das Center-Label dort sauber eingefügt werden konnte.
Über die gezählten Iterationen hinaus
Die fünf beschriebenen Iterationen lesen sich geordneter als sie waren. Design-Entscheidungen in der Praxis erfordern manchmal mehrere Durchläufe zum gleichen Thema: das Layout sieht im Browser anders aus als gedacht, die Anpassung geht in die richtige Richtung, aber noch nicht ganz weit genug, und man korrigiert erneut. Was zählt ist das Ergebnis, nicht die Anzahl der Prompts die es gebraucht hat.
Visueller Vergleich
Drei Browsertabs nebeneinander, gleicher Datensatz, drei verschiedene Antworten. Die Treemap beantwortet in zwei Sekunden die einfachste Frage: welcher Einzelplan ist am größten? Fläche ist Größe, und das liest man sofort. Der Sunburst beantwortet etwas Feineres: welche Hauptgruppen dominieren innerhalb eines bestimmten EPL, und wie verteilen sich Einnahmen und Ausgaben? Die ringförmige Hierarchie macht das greifbar. Das Sankey schließlich macht Flüsse sichtbar. Wer einen bestimmten Einnahme-Typ verfolgen will, folgt einfach der Linie bis zu den Einzelplänen und weiter zu den Ausgaben.
Drei Fragen, drei Visualisierungen. Keiner der drei war klar besser; sie waren schlicht unterschiedlich.
Entscheidung — keiner wird verworfen
Karpathys Worktree-Workflow legt nahe: einer gewinnt, die anderen verschwinden. Aber: drei Visualisierungen beantworten drei unterschiedliche Fragen. Eine erzwungene Wahl würde zwei Drittel der Information wegwerfen.
Entscheidung: alle drei in main mergen, per Switcher in der App wählbar.
// web/src/App.tsx
const VARIANTS = [
{ key: "sunburst", label: "Sunburst" },
{ key: "sankey", label: "Sankey" },
{ key: "treemap", label: "Treemap" },
];
const [variant, setVariant] = useState<Variant>("sunburst");
// <nav role="tablist"> mit drei Buttons
// {variant === "sunburst" && <Sunburst ... />}
// usw.
Default-Auswahl: Sunburst. Zeigt am meisten Informationen auf einen Blick. Die anderen zwei sind einen Klick entfernt.
Die Worktree-Branches frontend/treemap, frontend/sunburst, frontend/sankey bleiben erhalten. Sie sind das historische Artefakt des Vergleichs. Wer den Iterationsweg nachvollziehen will, kann jeden Branch isoliert auschecken.
Iterationen nach dem Merge
Die Entscheidung ist gefallen, die drei Branches sind in main. Damit ist die Arbeit nicht vorbei, denn im Browser wird sichtbar, was im Worktree-Vergleich noch nicht aufgefallen ist.
Hierarchie um eine Ebene tiefer
Erste Implementierung: vier Ebenen root → EPL → Hauptgruppe → Titel. Prompt:
Im Sunburst ist nicht klar, wann man Einnahmen und wann Ausgaben sieht.
Füge eine Ebene dazwischen: erst Einnahmen oder Ausgaben wählen, dann die Einzelpläne.
Die Lösung: kind als eigene Ebene direkt unter root.
root → kind (Einnahmen/Ausgaben) → epl → hauptgruppe → titel
Jeder kind-Knoten bekommt seinen eigenen Subtree. Ein Klick auf „Ausgaben" zeigt ausschließlich Ausgaben-EPLs, ohne Gemisch.
Drill-Down via focusPath, nicht via nodeKey
Eine erste Klick-Implementation berechnete einen zusammengesetzten Key und suchte den Knoten im vollen Baum zurück. Prompt:
Bug: Wenn ich auf Ausgaben klicke und dann auf einen Einzelplan,
springt er zur Vollansicht zurück statt tiefer reinzuzoomen.
Das Problem lag im State-Design: nach einem ersten Drill in den Sub-Baum hatten die Knoten dort keine Vorgänger mehr, das Walk-Up landete am falschen Punkt. Das Symptom war eindeutig: Ein Klick auf einen EPL nach Zoom auf „Ausgaben" sprang zurück zur Vollansicht statt tiefer zu gehen.
Die richtige Lösung war, den State nicht als zusammengesetzten String-Key, sondern als Pfad-Array zu führen, mit einem Identifier pro Drill-Schritt:
const [focusPath, setFocusPath] = useState<string[]>([]);
// Beim Klick: lokalen Pfad vom Sub-Root aufbauen, an bestehenden Path anhängen
const pathFromSubRoot: string[] = [];
let cur = clickedNode;
while (cur && cur !== subRoot) {
pathFromSubRoot.unshift(identifierOf(cur.data));
cur = cur.parent;
}
setFocusPath([...focusPath, ...pathFromSubRoot]);
Lesson: Drill-Down-State als Pfad-Array führen, nicht als String-Key über Sub-Hierarchien hinweg.
Kurze Codes in der Grafik, volle Namen in der Tabelle
Einen Schritt weiter stellte sich heraus, dass Truncate auf 22 Zeichen kein taugliches Label macht: „Einzelplan 11 Bayerisch…" sagt nichts. Der bessere Ansatz: die Visualisierung zeigt nur kurze Codes, die Tabelle daneben zeigt den vollen Namen mit Zeilenumbruch. Prompt:
Die langen Bezeichnungen in der Grafik funktionieren nicht — „Einzelplan 11 Bayerisch…" sagt nichts.
In der Grafik nur kurze Bezeichnungen wie EPL 1, HG 4, die volle Beschreibung daneben in der Tabelle.
Die Lösung: Grafik zeigt nur Codes (EPL 11, HG 4, Titel-Nummer), volle Bezeichnungen stehen in einer begleitenden Tabelle, die Zeilenumbruch erlaubt.
function shortLabelFor(data: HierarchyNode): string {
switch (data.level) {
case "epl": return `EPL ${parseInt(data.meta?.nr ?? "0", 10)}`;
case "hauptgruppe": return `HG ${data.meta?.nr}`;
case "titel": return data.meta?.nr ?? "";
default: return data.meta?.kind === "einnahme" ? "Einnahmen" : "Ausgaben";
}
}
Sunburst-Default als Halbkreis-Layout
Das nächste Layout-Problem zeigte sich beim Sunburst-Default: zwei Sektoren, Einnahmen und Ausgaben, nebeneinander in einem vollen Kreis ließen nicht intuitiv erkennen, was wo ist. Die Lösung war ein Halbkreis-Split: Einnahmen oben, Ausgaben unten, beschriftet durch HTML-Headings außerhalb des SVG. Prompt:
Wenn man Einnahmen und Ausgaben in einem vollen Kreis sieht, erkennt man nicht sofort welche Seite was ist.
Teile den Standardkreis in zwei Hälften: Einnahmen oben, Ausgaben unten.
Beschriftung "Einnahmen" und "Ausgaben" außerhalb des Kreises, als Überschrift.
Wenn man reinklickt, kommt wieder der normale volle Kreis.
Lösung: zwei separate d3.partition-Aufrufe mit size([π, RADIUS]), dann Angle-Offset:
// Einnahmen oben [-π/2, π/2]
einnRoot.each((d) => { d.x0 -= Math.PI / 2; d.x1 -= Math.PI / 2; });
// Ausgaben unten [π/2, 3π/2]
ausgRoot.each((d) => { d.x0 += Math.PI / 2; d.x1 += Math.PI / 2; });
Beim Zoom (focusPath nicht leer): voller Kreis wie üblich. Die Beschriftung „Einnahmen" und „Ausgaben" steht als HTML-Heading über und unter dem SVG, nicht im Kreis.
Farben beim Zoom neu verteilt
Eine Farbfrage, die erst beim Zoom sichtbar wurde: im Default funktionieren rot und türkis als kind-Farben gut. Aber beim Zoom auf „Ausgaben" wäre plötzlich alles türkis und kein einziger EPL wäre vom anderen zu unterscheiden. Die Lösung war beim Zoom auf eine Tableau-Ordinal-Palette zu wechseln, eine eigene Farbe pro depth-1-Child:
const isDefault = focusPath.length === 0;
const colorFor = (d) => {
if (isDefault) return KIND_COLORS[d.data.meta?.kind ?? "ausgabe"];
let n = d; while (n.depth > 1) n = n.parent;
return ordinal(identifierOf(n.data));
};
Center-Label zeigt beide Gesamtsummen
Das leere Zentrum im Default-Mode war die letzte offensichtliche Lücke: der Sunburst zeigte Einnahmen und Ausgaben, aber nirgendwo stand, wie viel das insgesamt ist. Die Mitte bekam drei Textzeilen: „Bayerischer Haushalt 2026" in Grau, darunter Σ Einnahmen in Rot und Σ Ausgaben in Türkis. Beim Zoom wechselt das Center auf den Namen des gewählten Knotens, seine Summe und ein klickbares „Zurück"-Signal, das einen Schritt aus dem focusPath entfernt.
Begleitende Tabellen mit Gruppierung
Erste Tabellen-Version: flache Liste. Anforderung: gruppiert nach Hauptelement, sortiert nach EPL-Nummer. Natural Sort über padded numerische Anteile:
function numericSortKey(data: HierarchyNode): string {
return (data.meta?.nr ?? "").replace(/\d+/g, (m) => m.padStart(8, "0"));
}
Default-Tabelle: Header „Ausgaben" + alle Ausgaben-EPL nach Nummer, dann Header „Einnahmen" + alle Einnahmen-EPL nach Nummer.
Treemap: Drill-Down und Text-Umbruch
Die erste Treemap zeigte zwei statische Panels, Einnahmen und Ausgaben getrennt, ohne Drill-Down. Um konsistent mit dem Sunburst zu sein, brauchte sie dieselbe focusPath-Logik und denselben Breadcrumb-Header. Das war schnell ergänzt. Die eigentliche Überraschung kam beim Text-Layout in den Kacheln: SVG-<text> bricht nicht automatisch um, und bei längeren EPL-Namen wurde das schnell zum Problem. Prompt:
Die Treemap soll auch anklickbar sein — Klick auf eine Kachel zoomt rein.
Oben ein Breadcrumb damit man weiß wo man ist und zurücknavigieren kann.
Die Bezeichnungen in den Kacheln sollen umbrechen wenn sie zu lang sind.
Darunter eine Tabelle mit den gleichen Einträgen wie im Sunburst.
Die Lösung über <foreignObject> mit einem HTML-<div> und Tailwinds break-words funktioniert sofort und erspart jeden manuellen Umbruch-Algorithmus:
<foreignObject x={0} y={0} width={w} height={h}>
<div className="text-white p-2 flex flex-col gap-1">
<div className="font-bold">{shortLabel}</div>
<div className="text-xs break-words">{fullName}</div>
<div className="text-xs font-mono">{formatTsdEuro(value)}</div>
</div>
</foreignObject>
Konsistenz über alle drei Varianten
Prompt für Sankey:
Mach den Sankey konsistent mit Sunburst und Treemap:
gleicher Header oben mit Gesamtsummen, kurze Codes in der Grafik,
Tabellen mit vollen Bezeichnungen daneben.
Das Hervorheben beim Klick soll bleiben wie es ist.
Sankey bekommt denselben Header (Σ Einnahmen und Σ Ausgaben, farbcodiert), dieselben kurzen Codes als Node-Labels, dieselben Tabellen mit Code + Name + Σ. Sankey behält das Highlight-bei-Klick-Verhalten, denn bei einem Fluss-Diagramm ist visuelles Fade-out aussagekräftiger als ein Subtree-Filter.
Das Ergebnis: drei Varianten, drei Entscheidungsfragen, eine gemeinsame Sprache aus Header, Codes, Tabellen.
Stand am Ende dieses Artikels
git clone https://codeberg.org/rotecodefraktion/byhaushalt.git
cd byhaushalt
git checkout v0.6
cd parser && uv run python -m parser.normalize
cd ../web && npm install && npm run dev
Vollständiger Stand unter byhaushalt @ v0.6.
v0.6 enthält: web/-Skelett mit Vite + React 19 + TS + Tailwind 4 + Vitest, drei Visualisierungs-Komponenten in web/src/charts/, Switcher in App.tsx, Parser erweitert um epl_name + kap_name, Hauptgruppen-Klassifikation in web/src/hauptgruppen.ts. 22 Tests grün, 3 xfail.
cd parser && uv run pytest -v
cd web && npm run test
# 22 passed, 3 xfailed
Wie geht es weiter
Artikel 7 behandelt MCP-Server. Statt Library-APIs aus dem Gedächtnis zu raten und damit halluzinierte Methoden zu produzieren, lädt Claude Code die aktuelle Doku der genutzten Libraries (D3, Vite, Vitest, Tailwind) per Context7-MCP-Server. Außerdem: Playwright-MCP als Vorbereitung für End-to-End-Tests in Artikel 8.
Wie Subagents das Datenmodell parallel gebaut haben, beschreibt Artikel 5. Slash Commands für wiederholbare Workflows zeigt Artikel 4.