Bonus: Wir bauen Lal — ein kleines Basismodell aus den Bauteilen der Serie

Bonus zur Serie · Wie LLMs funktionieren
In der Folge „The Offspring" baut Data, der Android aus Star Trek: The Next Generation, eine Tochter — Lal. Er nimmt das, was er ist, und setzt aus den eigenen Bauteilen ein neues, kleineres Wesen zusammen. Wir machen in diesem Bonus-Kapitel etwas Ähnliches, nur viel weniger dramatisch: Wir nehmen die Code-Fragmente aus den Artikeln 1 bis 8 (siehe Liste unten), fügen sie zu einem lauffähigen Mini-Sprachmodell zusammen, trainieren es auf einem Laptop und schauen, was am Ende herauskommt.
Das Modell heißt — natürlich — lal. Der Code liegt unter codeberg.org/rotecodefraktion/lal. Ziel ist nicht ein produktionsreifer LLM-Stack, sondern Verständlichkeit. Wer das Modell verstehen will, soll die einzelne Datei build_basemodel.py von oben nach unten lesen können und dabei die Konzepte aus der Serie wiedererkennen.
Was wir bauen
lal ist ein klassischer Decoder-only Transformer im Stil von GPT-2, in vier Größen:
| Config | Layer | Heads | Embedding | Kontext | Parameter |
|---|---|---|---|---|---|
tiny | 4 | 4 | 128 | 128 | ~3M |
small | 6 | 6 | 384 | 256 | ~30M |
medium | 8 | 8 | 512 | 512 | ~50M |
lal | 12 | 12 | 768 | 512 | ~120M |
Die lal-Config orientiert sich grob an GPT-2 small (124M), die kleineren sind vor allem da, damit auch ein älteres MacBook oder ein 8-GB-Notebook das Skript zum Laufen bringt. Trainingsdaten sind die TinyShakespeare-Textdatei (ca. 1 MB), wie bei Karpathys nanoGPT — public domain, klein genug für Laptop-Training, groß genug, dass das Modell tatsächlich Muster lernt statt nur auswendig.
Die Bausteine, die wir schon haben
Wenn wir die Serie zurückspulen, sind folgende Bausteine bereits da:
- Artikel 1, Was ist ein Sprachmodell — die Grundidee „nächstes Token vorhersagen", Cross-Entropy als Trainingsziel.
- Artikel 2, Embeddings — Tokens als Vektoren, ein Vokabular von IDs.
- Artikel 3, Neuronale Netze — Linear-Layer, Aktivierungsfunktionen, Feed-Forward-Netze.
- Artikel 4, Backpropagation — Forward, Loss, Backward, Optimizer-Step.
- Artikel 5, Kontext und RNNs — wir haben gesehen, warum RNNs nicht reichen.
- Artikel 6, Attention — Self-Attention, Multi-Head, kausale Masken.
- Artikel 7, Transformer — der vollständige Block mit Pre-LayerNorm und Residual.
- Artikel 8, Fine-Tuning — was nach dem Pretraining kommt (kürzen wir auf einen Mini-SFT-Schritt am Ende ein).
Was wir in der Praxis dazu brauchen: einen funktionierenden Tokenizer (kein selbstgebauter, dafür ist das hier nicht der richtige Artikel), einen Trainings-Loop mit Batch-Sampling und Checkpoint-Logik, und ein Sampling-Verfahren mit Top-k und Temperatur. Alles drei sind in build_basemodel.py implementiert, jeweils mit einem Header-Kommentar, der auf den Serien-Artikel verweist.
Setup: uv, PyTorch, Hardware
Wir benutzen uv als Python-Paket-Manager. Das spart die übliche python -m venv .venv && source .venv/bin/activate && pip install -r requirements.txt-Routine — uv sync macht alles in einem Schritt:
git clone https://codeberg.org/rotecodefraktion/lal.git
cd lal
uv sync
Das Repository hat eine pyproject.toml mit den Dependencies (torch, tiktoken, numpy, matplotlib) und nutzt uv.lock für reproduzierbare Builds. Wer noch kein uv installiert hat: brew install uv auf macOS oder curl -LsSf https://astral.sh/uv/install.sh | sh plattformübergreifend.
PyTorch erkennt die Hardware automatisch. Auf Apple Silicon nutzen wir den MPS-Backend (Metal Performance Shaders), auf NVIDIA-Karten CUDA, sonst CPU. Die Erkennung steckt in build_basemodel.py:
def get_device() -> torch.device:
if torch.cuda.is_available():
return torch.device("cuda")
if torch.backends.mps.is_available():
return torch.device("mps")
return torch.device("cpu")
Welche Config welche Hardware verträgt, ist Erfahrungssache. Mein Trainingslauf der lal-Config (120M Parameter) auf einem M4 Air mit 24 GB unified memory war an der Grenze — RAM bei 89%, knapp 4 GB Swap aktiv, GPU bei 91% Auslastung. Geht, ist aber langsam und stresst die SSD. Auf einem M3 Max mit 64 GB läuft die gleiche Config ohne Swap und ungefähr dreimal schneller. Die saubere Empfehlung: M4 Air → medium, M-Max-Klasse → lal.
Apple Silicon (Mac, PyTorch MPS-Backend):
| Hardware | Getestet | Trainingszeit (bis Early-Stop) |
|---|---|---|
| M4 Air 24 GB | small (30M) | 95.5 min (early-stop iter 1750, best @ iter 750) |
| M3 Max 64 GB | lal (120M) | 35.4 min (early-stop iter 2250, best @ iter 1250) |
Apple Silicon (Mac, MLX-Backend, separate Implementierung):
| Hardware | Getestet | Trainingszeit (bis Early-Stop) |
|---|---|---|
| M4 Air 24 GB | small (30M) | 100.9 min¹ (early-stop iter 1750, best @ iter 750) |
| M3 Max 64 GB | lal (120M) | 23.8 min (early-stop iter 2000, best @ iter 1000) |
¹ Während dieses Laufs lief Claude Code parallel und hat etwa 30 % der GPU-Last verbraucht. Bereinigt landet der MLX-Lauf bei rund 77 Minuten.
NVIDIA (CUDA-Stack, andere Plattform — als Referenz):
| Hardware | Empfohlen | Trainingszeit |
|---|---|---|
| RTX 3060 12 GB | small (30M) | n/a (nicht selbst getestet) |
| RTX 4090 24 GB | lal (120M) | n/a (nicht selbst getestet) |
Die drei Tabellen sind bewusst getrennt. Apple Silicon und NVIDIA sind unterschiedliche GPU-Stacks (Metal vs CUDA), und auf Apple Silicon selbst existieren mit PyTorch-MPS und MLX zwei Frameworks mit deutlichen Performance-Unterschieden. Auf den MLX-Port kommen wir gleich nochmal zurück — er ist als zweite, parallele Implementierung im Repository.
Schritt 1: Tokenization mit tiktoken
In Artikel 2 haben wir Tokenization als Konzept eingeführt: Text in Stücke zerlegen, jedes Stück bekommt eine ID, das Modell sieht nur die IDs. Theoretisch könnten wir char-level tokenisieren — jedes Zeichen ein Token —, das wäre maximal didaktisch, produziert aber sehr lange Sequenzen für wenig Information. Im echten Stack nutzt heute jedes Frontier-Modell BPE (Byte Pair Encoding), und das machen wir auch.
Wir greifen zu OpenAIs tiktoken, genauer dem r50k_base-Encoding (das von GPT-2). Tiktoken ist ein BPE-Tokenizer mit etwa 50.257 Tokens, in Rust geschrieben, sehr schnell. Es kapselt den Algorithmus als Black Box — wer sehen will wie BPE intern arbeitet, sollte Karpathys minbpe anschauen. Für uns reicht es zu wissen: häufige Sequenzen werden ein Token, seltene splittet es in mehrere. „Hallo Welt" wird zu drei oder vier Tokens, „Antidisestablishmentarianismus" wird in seine üblichen Bestandteile zerlegt.
In Code:
import tiktoken
_ENCODER = tiktoken.get_encoding("r50k_base")
def encode(text: str) -> list[int]:
return _ENCODER.encode(text)
def decode(ids: list[int]) -> str:
return _ENCODER.decode(ids)
Das Vokabular von 50.257 Tokens definiert auch die vocab_size unseres Modells — die Output-Schicht wird genau so viele Werte produzieren wie es Tokens im Vokabular gibt.
Schritt 2: Embeddings
In Artikel 2 haben wir Embeddings als Vektoren in einem hochdimensionalen Raum eingeführt. In PyTorch ist das eine nn.Embedding-Schicht, die für jede Token-ID einen Vektor aus einer trainierbaren Matrix abruft:
self.token_emb = nn.Embedding(cfg.vocab_size, cfg.n_embd)
Dazu kommt eine zweite Embedding-Tabelle für Positionen — der Positional Embedding aus Artikel 7. Ohne den wüsste das Modell nicht, ob ein Token am Anfang oder am Ende des Kontexts steht:
self.pos_emb = nn.Embedding(cfg.block_size, cfg.n_embd)
Im Forward-Pass werden beide addiert:
pos = torch.arange(T, device=idx.device)
x = self.token_emb(idx) + self.pos_emb(pos)
Das ist die einfachste Form von Position. Modernere Varianten — RoPE bei Llama, ALiBi bei einigen Modellen — sind eleganter, aber für ein didaktisches Modell tut es absolutes Positional Embedding völlig.
Schritt 3: Multi-Head Attention
Der Kern aus Artikel 6. Self-Attention berechnet für jede Position eine Mischung aus allen vorherigen Positionen. Q, K, V sind drei lineare Projektionen des Inputs. Score gleich Q mal K-transponiert geteilt durch Wurzel(d_k), dann Softmax, dann mit V multiplizieren.
„Multi-Head" heißt, wir teilen den Embedding-Raum in n_head Stücke und berechnen Attention parallel pro Head. Jeder Head kann andere Muster lernen.
„Causal" heißt, jede Position darf nur auf sich selbst und vorherige Positionen schauen. Sonst würde das Modell beim Training die Antwort einfach ablesen. Die Maske ist ein oberes Dreieck aus minus unendlich, das vor dem Softmax addiert wird.
class MultiHeadAttention(nn.Module):
def __init__(self, cfg: ModelConfig):
super().__init__()
self.n_head = cfg.n_head
self.head_dim = cfg.n_embd // cfg.n_head
self.qkv = nn.Linear(cfg.n_embd, 3 * cfg.n_embd, bias=False)
self.proj = nn.Linear(cfg.n_embd, cfg.n_embd, bias=False)
mask = torch.tril(torch.ones(cfg.block_size, cfg.block_size))
self.register_buffer("mask", mask.view(1, 1, cfg.block_size, cfg.block_size))
def forward(self, x):
B, T, C = x.shape
q, k, v = self.qkv(x).chunk(3, dim=-1)
q = q.view(B, T, self.n_head, self.head_dim).transpose(1, 2)
k = k.view(B, T, self.n_head, self.head_dim).transpose(1, 2)
v = v.view(B, T, self.n_head, self.head_dim).transpose(1, 2)
att = (q @ k.transpose(-2, -1)) / math.sqrt(self.head_dim)
att = att.masked_fill(self.mask[:, :, :T, :T] == 0, float("-inf"))
att = F.softmax(att, dim=-1)
out = att @ v
out = out.transpose(1, 2).contiguous().view(B, T, C)
return self.proj(out)
Das ist die kanonische Implementation — und gleichzeitig die dichteste Stelle der ganzen Datei. Fünf Stellen lohnen einen genaueren Blick.
Eine Linear-Schicht für Q, K und V auf einmal. Statt drei separate nn.Linear(C, C) zu bauen, machen wir einen einzelnen nn.Linear(C, 3*C) und splitten das Ergebnis mit .chunk(3, dim=-1). Mathematisch identisch, in der Praxis ein GPU-Geschwindigkeitsgewinn — eine große Matrix-Multiplikation statt drei kleinen.
Shape-Tracking. Input x hat Shape (B, T, C) — B Batch-Größe, T Anzahl Tokens, C Embedding-Dimension. Nach qkv(x): (B, T, 3*C). Nach chunk: drei Tensoren mit (B, T, C). Die Operation view(B, T, n_head, head_dim).transpose(1, 2) zerlegt die C-Dimension in n_head Stücke à head_dim und schiebt die Head-Achse nach vorn → (B, n_head, T, head_dim). Ab hier rechnen alle folgenden Matrix-Operationen automatisch parallel über alle Heads — der Trick, der „Multi-Head" überhaupt billig macht.
Skalierung mit sqrt(head_dim). q @ k.transpose(-2, -1) ergibt einen Score-Tensor (B, n_head, T, T): für jeden Head, jede Position i, jede Position j ein Aufmerksamkeits-Score. Die Division durch sqrt(head_dim) ist nicht kosmetisch. Ohne sie wachsen die Scores mit head_dim, der Softmax kollabiert in eine 1-Hot-Verteilung (alles auf eine Position konzentriert), und der Gradient verschwindet, weil ein gesättigter Softmax keine ableitbare Information mehr liefert. Die Wurzel kompensiert genau diesen Skalierungs-Effekt.
Causal Mask. Die tril-Maske ist ein unteres Dreieck aus Einsen, der Rest Null. masked_fill(... == 0, -inf) setzt alles oberhalb der Diagonale auf -inf; nach Softmax werden diese Positionen zu exakt 0. Folge: Token an Position t sieht nur Tokens 0..t, nie die Zukunft. Wir registrieren die Maske als Buffer (kein trainierbarer Parameter, wandert aber mit dem Modell aufs Device) und schneiden mit [:, :, :T, :T] auf die aktuelle Sequenzlänge zu — beim Sampling kürzer als block_size.
Heads zurückführen. att @ v ergibt (B, n_head, T, head_dim), dann packt transpose(1, 2).contiguous().view(B, T, C) die Heads wieder zur flachen Embedding-Dimension zusammen. Der finale proj-Layer ist wichtig: ohne ihn wären die Heads nach dem Concat unabhängige Stücke — proj mischt Information zwischen ihnen, bevor das Ergebnis zurück in den Residual-Stream geht.
Wer Wert auf Geschwindigkeit legt, ersetzt den ganzen Score-Block durch F.scaled_dot_product_attention, das in PyTorch 2 hardware-spezifisch optimiert ist (Flash Attention auf NVIDIA, Memory-Efficient Attention auf MPS). Für Lesbarkeit bleiben wir bei der expliziten Form.
Schritt 4: Der Transformer-Block
Aus Artikel 7. Ein Block ist Attention plus Feed-Forward, beides mit Pre-LayerNorm und Residual:
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.ln1 = nn.LayerNorm(cfg.n_embd)
self.attn = MultiHeadAttention(cfg)
self.ln2 = nn.LayerNorm(cfg.n_embd)
self.ffn = FeedForward(cfg)
def forward(self, x):
x = x + self.attn(self.ln1(x))
x = x + self.ffn(self.ln2(x))
return x
Pre-LN (LayerNorm vor dem Sublayer, nicht danach) ist die moderne Variante; sie trainiert stabiler bei tiefen Modellen. Das war in den Original-Transformer-Papern noch andersrum (Post-LN), inzwischen hat sich Pre-LN durchgesetzt.
Das Feed-Forward-Netz ist ein klassisches MLP aus Artikel 3:
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.net = nn.Sequential(
nn.Linear(cfg.n_embd, 4 * cfg.n_embd),
nn.GELU(),
nn.Linear(4 * cfg.n_embd, cfg.n_embd),
nn.Dropout(cfg.dropout),
)
def forward(self, x):
return self.net(x)
Der Hidden-Layer ist 4× breiter als das Embedding — das ist der GPT-Standardwert, ohne tiefere Theorie. Mehr Kapazität pro Block.
Schritt 5: Das ganze Modell
Embeddings, n Blöcke, finaler LayerNorm, Output-Head. Eine kleine Eleganz: der Output-Head teilt sich seine Gewichte mit der Token-Embedding-Matrix (Weight Tying). Spart Parameter und funktioniert in der Praxis besser:
class GPT(nn.Module):
def __init__(self, cfg):
super().__init__()
self.token_emb = nn.Embedding(cfg.vocab_size, cfg.n_embd)
self.pos_emb = nn.Embedding(cfg.block_size, cfg.n_embd)
self.blocks = nn.ModuleList([TransformerBlock(cfg) for _ in range(cfg.n_layer)])
self.ln_f = nn.LayerNorm(cfg.n_embd)
self.head = nn.Linear(cfg.n_embd, cfg.vocab_size, bias=False)
self.head.weight = self.token_emb.weight # Weight Tying
def forward(self, idx, targets=None):
B, T = idx.shape
pos = torch.arange(T, device=idx.device)
x = self.token_emb(idx) + self.pos_emb(pos)
for block in self.blocks:
x = block(x)
x = self.ln_f(x)
logits = self.head(x)
loss = None
if targets is not None:
loss = F.cross_entropy(
logits.view(-1, logits.size(-1)),
targets.view(-1),
)
return logits, loss
Drei Dinge sind hier nicht sofort offensichtlich.
Forward-Pass als Shape-Story. Input idx ist eine Token-ID-Matrix mit Shape (B, T) — B Sequenzen aus dem Batch, jeweils T Token-IDs lang. Nach den beiden Embedding-Lookups plus Addition haben wir (B, T, n_embd). Diese Shape bleibt durch alle n_layer Blöcke konstant — Attention und FFN sind shape-erhaltend. Nach dem finalen LayerNorm und dem head-Layer ist die Shape (B, T, vocab_size): für jede Position eine vollständige Wahrscheinlichkeitsverteilung über alle möglichen nächsten Tokens.
Weight Tying. Die Zeile self.head.weight = self.token_emb.weight lässt Output-Projektion und Token-Embedding sich dieselbe Matrix teilen. Konzeptionell sinnvoll: Token-Embedding mappt ID → Vektor, der Output-Head macht das Umgekehrte (Vektor → Logits über alle IDs). Beide brauchen denselben „Wörterbuch"-Raum. In Zahlen: bei vocab_size=50257 und n_embd=384 spart das eine 50257 × 384 Matrix ≈ 19,3 Millionen Parameter — fast zwei Drittel des small-Modells. Empirisch lernt das Modell so auch besser, weil die Repräsentationen konsistent zwischen Eingang und Ausgang bleiben.
Cross-Entropy mit Reshape. F.cross_entropy erwartet 2D-Logits (N, C) und 1D-Targets (N,). Wir haben aber 3D-Logits (B, T, vocab_size) und 2D-Targets (B, T). Die view(-1, ...)-Aufrufe flatten Batch und Zeit zu einer einzigen Achse: aus (B, T, vocab_size) wird (B*T, vocab_size), aus (B, T) wird (B*T,). Konzeptionell behandeln wir jede Position in jeder Sequenz als ein eigenständiges Klassifikationsproblem mit 50.257 Klassen, PyTorch mittelt am Ende über alle B*T Positionen — das ist der Loss-Wert, den wir später im Trainings-Log sehen.
Das war’s an Modell-Code. Vier Klassen — MultiHeadAttention, FeedForward, TransformerBlock, GPT — plus ModelConfig und ein paar Helper, alle in einer Datei, alle direkt aus den Serien-Artikeln.
Schritt 6: Training
Standard-Loop aus Artikel 4: Forward, Loss, Backward, Optimizer-Step. Plus Eval-Schritte alle paar Iterationen, plus Cosine-Schedule mit Warmup für die Lernrate, plus Gradient-Clipping gegen exploding gradients.
def train(cfg, checkpoint_path):
device = get_device()
train_data, val_data = load_data()
model = GPT(cfg).to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=cfg.learning_rate,
betas=(0.9, 0.95), weight_decay=0.1)
for it in range(cfg.max_iters + 1):
lr = lr_schedule(it, cfg)
for pg in optimizer.param_groups:
pg["lr"] = lr
if it % cfg.eval_interval == 0:
losses = estimate_loss(model, train_data, val_data, cfg, device)
print(f"iter {it} | train {losses['train']:.4f} | val {losses['val']:.4f}")
x, y = get_batch(train_data, cfg.block_size, cfg.batch_size, device)
_, loss = model(x, y)
optimizer.zero_grad(set_to_none=True)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), cfg.grad_clip)
optimizer.step()
torch.save({"model": model.state_dict(), "config_name": cfg.name}, checkpoint_path)
Der Loop ist Standard, ein paar Details sind aber nicht-trivial.
get_batch zieht zufällige Window-Positionen aus dem flach geladenen Token-Tensor: B Startpunkte werden zufällig gesampelt, je block_size Tokens als Input, der um eins versetzte Slice als Target. Kein DataLoader-Objekt, kein Multi-Worker — torch.randint plus Slicing reicht. Funktioniert nur, weil unser Datensatz komplett in den RAM passt; bei großen Korpora wäre das anders.
optimizer.zero_grad(set_to_none=True) löscht die Gradienten vom letzten Step. set_to_none=True ist effizienter als das alte Verhalten („auf Null setzen"): statt jeden Gradient-Tensor zu nullen, wird er einfach freigegeben. Spart einen Memory-Pass durch alle Parameter.
loss.backward() löst Backpropagation aus. PyTorch hat während des Forward-Passes ein „Tape" mitlaufen lassen, das sich an jede Operation und ihre Eingaben erinnert. backward läuft dieses Tape rückwärts und füllt für jeden Parameter-Tensor das .grad-Feld. Der eigentliche Algorithmus aus Artikel 4, hier in einer einzigen Zeile.
clip_grad_norm_(model.parameters(), grad_clip) berechnet die L2-Norm über alle Gradienten zusammen und skaliert sie herunter, falls sie über grad_clip (typisch 1.0) liegt. Schutz gegen einzelne Iterationen, in denen ein Gradient explodiert und die Gewichte in eine schlechte Region schiebt. Ohne diesen Trick ist Transformer-Training mit hoher Wahrscheinlichkeit instabil — eine schlechte Iteration reicht, um die Konvergenz zu zerstören.
optimizer.step() wendet die AdamW-Update-Regel an: jeder Parameter bekommt einen kleinen Schritt in Richtung negativer Gradient, gewichtet mit den Adam-Momenten (gleitende Mittelwerte von Gradient und Gradient-Quadrat). Das W in AdamW steht für „Weight Decay entkoppelt": L2-Regularisierung wird direkt nach dem Parameter-Update angewendet, nicht in den Gradient gemischt. Konvergiert in der Praxis besser als klassisches L2-Decay.
Eval-Schritt alle eval_interval Iterationen: estimate_loss zieht mehrere Mini-Batches aus Train- und Val-Daten und mittelt den Loss. Das ist unser Logging-Signal — und Input für die Early-Stopping-Logik (siehe Overfitting-Sektion gleich).
Cosine-Schedule mit Warmup: lr_schedule(it, cfg) gibt für jede Iteration eine Lernrate zurück. Erste paar hundert Iterationen linear hoch (Warmup), dann eine halbe Cosine-Welle hinunter auf nahe Null. Adam braucht ein paar Schritte, um seine Momenten-Schätzungen zu stabilisieren; gegen Ende der Konvergenz hilft eine kleine Lernrate, das Minimum genauer zu treffen statt drumherum zu oszillieren.
AdamW-Betas (0.9, 0.95) sind der GPT-Standard, leicht abweichend von den PyTorch-Defaults (0.9, 0.999). Der niedrigere zweite Beta lässt den Optimizer schneller auf neue Gradient-Statistiken reagieren — gut für Sprachmodell-Training, wo der Loss-Landscape sich mit fortschreitendem Training schnell ändert.
Was sehen wir auf der Konsole, während das trainiert? Auf einem M4 Air mit 24 GB, --config small (~30M effektive Parameter):
Device: mps
Config: small (~30.0M Parameter)
Train-Tokens: 304,222 — Val-Tokens: 33,803
iter 0 | train 10.8746 | val 10.8710 | lr 3.00e-06 | 2.0 min *
iter 250 | train 4.5904 | val 5.1055 | lr 2.99e-04 | 15.2 min *
iter 500 | train 3.9147 | val 4.7649 | lr 2.95e-04 | 28.7 min *
iter 750 | train 3.4834 | val 4.7376 | lr 2.87e-04 | 41.9 min *
iter 1000 | train 3.0431 | val 4.8332 | lr 2.76e-04 | 55.5 min
iter 1250 | train 2.6174 | val 4.9939 | lr 2.61e-04 | 68.9 min
iter 1500 | train 2.1891 | val 5.1886 | lr 2.44e-04 | 82.4 min
iter 1750 | train 1.7713 | val 5.4638 | lr 2.24e-04 | 95.4 min
Early stopping: keine Val-Loss-Verbesserung seit 4 Evals (best @ iter 750: 4.7376).
Trainingszeit gesamt: 95.5 min.
Der initiale Loss von ~10.87 entspricht ungefähr ln(vocab_size) = ln(50257) ≈ 10.83 — das Modell rät am Anfang gleichverteilt unter allen Tokens, was die Cross-Entropy genau da hinsetzt. Nach 250 Iterationen fällt der Train-Loss auf 4.59, der Val-Loss auf 5.11 — das Modell hat die Token-Häufigkeitsverteilung gelernt. Bis iter 750 sinkt beides weiter, der Val-Loss erreicht sein Minimum von 4.74.
Und dann passiert etwas Lehrreiches.
Was schiefgeht: Overfitting auf TinyShakespeare
Ab iter 750 läuft Train-Loss und Val-Loss auseinander. Train fällt weiter (von 3.48 auf 1.77 nach iter 1750, wo Early-Stopping greift), Val klettert wieder hoch (von 4.74 auf 5.46, schlechter als nach iter 500). Das ist die klassische Overfit-Signatur: das Modell lernt den Trainingstext auswendig, statt zu generalisieren. Ohne Early-Stopping würde der Train-Loss weiter Richtung Null fallen, der Val-Loss weiter steigen.
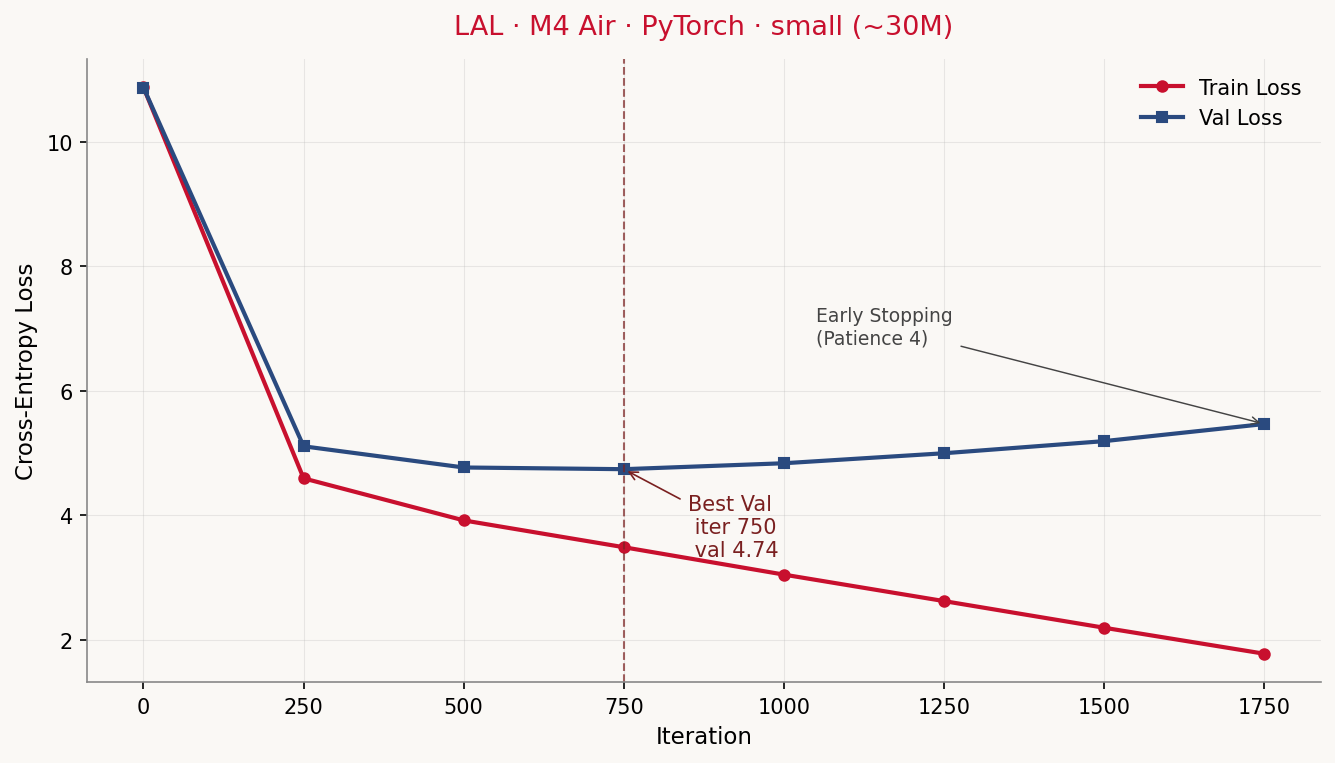
Warum? Die Mathematik dahinter ist unbarmherzig. Wir haben ~304.000 Trainings-Tokens und ein Modell mit ~30 Millionen Parametern, davon allein 19 Millionen im Token-Embedding (50.257 Vocabulary-Einträge × 384 Embedding-Dimensionen). Die Embedding-Matrix hat fast 60× mehr Parameter als der Trainingstext Tokens enthält. Das Modell hat genug Kapazität, um den gesamten Trainingstext schlicht zu memorisieren.
Diese Imbalance zwischen Vokabular und Datenmenge ist eine Eigenheit unseres Setups: BPE-Vokabulare wie r50k_base sind für Internet-skalige Korpora gebaut, nicht für 1 MB Shakespeare. nanoGPT macht das anders — Karpathy nutzt für TinyShakespeare einen char-level Tokenizer mit 65 Tokens. Damit ist das Token-Embedding klein (65 × 384 ≈ 25k Parameter), und das Modell kann die Datenmenge sinnvoll verarbeiten.
Wir bleiben bei tiktoken, weil es ehrlicher die Realität abbildet, in der echte LLMs leben. Aber das hat einen Preis: Overfitting kommt früh und brutal.
Drei pragmatische Antworten darauf, in zunehmender Aggressivität:
- Early Stopping. Wir tracken den Val-Loss bei jedem Eval-Schritt und speichern das Modell separat, wenn der Val-Loss verbessert. Wenn er für N Evals nicht mehr besser wird, brechen wir ab. Im Code:
cfg.patience = 4. Praktisch: das Training stoppt automatisch bei iter 1750 statt am konfigurierten Maximum von iter 5000, mit dem besten Checkpoint von iter 750. - Kleinere Konfiguration. Mit
--config tiny(3M Parameter) ist die Embedding-Dominanz weniger erdrückend, die Generalisierung hält länger. - Mehr Dropout, mehr Daten. Beides würde helfen, sprengt aber den Rahmen dieses Bonus-Artikels. Wer ernsthaft TinyShakespeare-Generation will, nimmt nanoGPT mit char-level Tokenizer.
Im aktuellen Code ist Early Stopping default. Der finale Checkpoint heißt checkpoints/<config>.pt, der Best-Checkpoint checkpoints/<config>_best.pt. Für Sampling immer den Best-Checkpoint nehmen — der finale ist überfittet.
Schritt 7: Sampling
Trainiertes Modell, jetzt soll es generieren. Auto-regressiv: ein Token nach dem anderen. Top-k-Sampling (nur die k wahrscheinlichsten Tokens kommen in Frage) plus Temperatur (skaliert die Logit-Verteilung — hoch = experimenteller, niedrig = konservativer):
@torch.no_grad()
def generate(self, idx, max_new_tokens, temperature=1.0, top_k=50):
for _ in range(max_new_tokens):
idx_cond = idx[:, -self.cfg.block_size:]
logits, _ = self(idx_cond)
logits = logits[:, -1, :] / temperature
if top_k is not None:
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
logits[logits < v[:, [-1]]] = float("-inf")
probs = F.softmax(logits, dim=-1)
next_id = torch.multinomial(probs, num_samples=1)
idx = torch.cat([idx, next_id], dim=1)
return idx
Mit unserem best-Checkpoint trainierten Modell (M4 Air, PyTorch, small-Config, iter 750, val-Loss 4.74) sieht der Output zum Prompt "ROMEO:" so aus:
ROMEO:
I will be so, good night.
JULIET:
What you will, how, go; I do you hence with you?
ROMEO:
I speak, we must not be a son.
ROMEO:
Why, go and then, there is that?
ROMEO:
I will have her not, the man, sir;
BENVOLIO:
As you say you shall not do speak to be.
ROMEO:
Why, what?
ROMEO:
O, if any of that in the devil and
I'll speak an a word that I will be that thou.
ROMEO:
I have no more than any thing that?
MERCUTIO:
I'll tell the devil.
MERCUTIO:
Not that love, so, in, I must do it.
ROMEO:
Good love I will never
Erkennt Versmaß und das Capitalize-Pattern bei Sprecherwechseln, kennt die richtigen Sprecher (Romeo, Juliet, Benvolio, Mercutio), hat Shakespeare-Vokabular, ist aber inhaltlich Unsinn. Das ist der Punkt: ein Modell mit 30M Parametern auf 1 MB Text lernt Form, nicht Inhalt.
Zum Vergleich auf derselben Hardware, derselben small-Config, aber mit dem MLX-Backend statt PyTorch (best-Checkpoint, iter 750, val-Loss 4.74):
ROMEO:
I have a man of a man,
And I am a man that I am a man.
ROMEO:
O, I have a man of a man.
ROMEO:
O, I have a man of a man.
ROMEO:
O, that thou art a man of a man.
ROMEO:
O, thou art a man of a man, and a man.
ROMEO:
O, thou art a man of a man.
ROMEO:
O, that thou art a man of a man,
ROMEO:
O, that thou art a man'st, and a man,
And thou art a man of a man,
And thou art a man of a man, and a man,
And thou art a man that thou art a man, a man,
And thou art a
Trotz fast identischem Val-Loss landet MLX in einer Mode-Collapse-Schleife („a man of a man"). Beide Modelle haben dieselbe Architektur, dieselben Hyperparameter, fast identischen Loss — und produzieren sehr unterschiedliche Outputs. Bei kleinen Modellen am unteren Rand der Verständlichkeit ist Sampling-Qualität fragiler, als die Loss-Zahl suggeriert. Für das Bonus-Kapitel zeigt das nebenbei: Loss-Vergleich allein reicht nicht; für sinnvolle Aussagen über Modellqualität braucht es Outputs, idealerweise viele und mit verschiedenen Prompts.
Auf größerer Hardware mit der lal-Config (M3 Max, PyTorch, 123.9M Parameter, iter 1250, val-Loss 4.72) wird der Output deutlich flüssiger:
ROMEO:
Ah, or thou dost not myself,
That liege, then thou shalt not kill thy counsel.
KING RICHARD II:
I am thy death, I in thee,
Or thou canst see thee,
To make me to give thee,
And I with thee with my tongue
Than to thy land,
Of thou liest in thy state of thy shame,
And thou shalt thou shalt say
Of thy children'st thy breath,
And, though the ground the heart-t,
Thy grave, thyself for thy father's grave.
Mehr Parameter, längerer Trainingslauf bis zum besten Val-Loss, breiterer Kontext — und das Modell wechselt sogar selbständig in einen anderen Sprecher (King Richard II, der in TinyShakespeare ebenfalls vorkommt). Das wirkt jetzt fast wie ein echter Auszug. Ist es nicht. Wer das Stück kennt, sieht: die Sätze klingen, aber sie meinen nichts. Trotzdem zeigt der Sprung von small (30M) zu lal (123.9M), dass mehr Kapazität bei demselben winzigen Datensatz die Form noch glaubwürdiger macht.
Was wir nicht zeigen können (mangels Sample): der letzte, überfittete Checkpoint bei iter 1750, val-Loss 5.46. Erwartung: Outputs, die näher an wörtlichen Trainings-Sequenzen liegen, weil das Modell sie auswendig zu reproduzieren beginnt. Das ist auch ein gutes Anschauungsbeispiel: Overfit-Modelle wirken auf den ersten Blick „besser", weil ihre Outputs flüssiger sind — sind aber nutzlos für alles, was sie nicht direkt gesehen haben.
Bonus zum Bonus: derselbe Code in MLX
PyTorch ist die Standardbibliothek der ML-Welt, aber auf einem Mac läuft es nicht in seiner Heimat. Der MPS-Backend übersetzt PyTorch-Operationen zu Metal-Kernels — das geht, ist aber nicht das, was Apple Silicon eigentlich kann.
Apple selbst hat mit MLX ein eigenes Array-Framework gebaut, das von Anfang an für Unified Memory und die spezifische Architektur von M-Chips entworfen wurde. Es ist näher an NumPy/JAX als an PyTorch, und es ist auf Apple Silicon merklich schneller als PyTorch-MPS für die meisten Trainingsworkloads.
Im Repository liegt parallel zu build_basemodel.py eine zweite Datei: build_basemodel_mlx.py. Selbe Architektur, selbe Configs, selbes Trainingsskript — aber komplett in MLX statt PyTorch. Wer die Datei aufmacht, sieht direkt was der Wechsel bedeutet:
# PyTorch
model = GPT(cfg).to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=cfg.learning_rate)
x, y = get_batch(...)
_, loss = model(x, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# MLX
model = GPT(cfg)
mx.eval(model.parameters())
optimizer = optim.AdamW(learning_rate=cfg.learning_rate)
loss_and_grad = nn.value_and_grad(model, lambda m, x, y: m.loss(x, y))
x, y = get_batch(...)
loss, grads = loss_and_grad(model, x, y)
optimizer.update(model, grads)
mx.eval(model.parameters(), optimizer.state)
Drei Dinge fallen sofort auf:
Kein .to(device). MLX nutzt Apples Unified Memory nativ. Daten und Modellgewichte liegen einmal im RAM, GPU und CPU greifen darauf zu, ohne kopieren zu müssen. PyTorch-MPS hat zwar auch Zugriff auf Unified Memory, behält aber die CUDA-Logik bei, dass Tensors „auf einem Device" leben — was bei MPS zu unnötigen Memory-Layout-Konvertierungen führt.
Lazy Evaluation, explizites mx.eval(). MLX baut bei jeder Operation einen Compute-Graph auf. Erst beim mx.eval(...) (oder beim ersten .item()/Print) wird der Graph ausgeführt. Das gibt MLX die Möglichkeit, Operationen zu fusionieren — mehrere kleine MatMuls werden zu einem einzigen Kernel, Memory-Allokationen werden gestrichen, falls möglich.
nn.value_and_grad() statt loss.backward(). MLX folgt dem JAX-Stil: man definiert eine Funktion, die einen Loss zurückgibt, und MLX gibt einem eine zweite Funktion zurück, die zusätzlich die Gradienten liefert. Kein Autograd-Tape, das mitläuft, kein loss.backward(), das den Tape rückwärts auswertet. Reine Funktion → reine Funktion mit Gradienten.
Was das in der Praxis bringt, ist gemischter, als die MLX-Marketingseite suggeriert. Auf einem M3 Max mit der lal-Config (123.9M Parameter) braucht der PyTorch-MPS-Lauf bis zum Early-Stopping bei iter 2250 etwa 35.4 Minuten, der MLX-Lauf für das gleiche Modell 23.8 Minuten — Faktor 1.49× schneller. Auf einem M4 Air mit der small-Config (30M) sieht es weniger eindeutig aus: PyTorch 95.5 Minuten, MLX 100.9 Minuten — langsamer. Caveat: Während des MLX-Laufs lief Claude Code parallel und hat etwa 30 % der GPU-Last verbraucht; bereinigt landet der MLX-Lauf bei rund 77 Minuten, also Faktor ~1.24× schneller als PyTorch.
Faustregel: MLX gewinnt deutlicher bei größeren Modellen, wo Operator-Fusion und Memory-Effizienz mehr Gewicht haben. Bei kleinen Modellen ist der Unterschied im Rauschbereich, und Hintergrundlast (andere GPU-Anwendungen, Browser mit Hardware-Beschleunigung) kann den Vorteil schnell auffressen. Für ehrliche Vergleichszahlen immer Single-Workload-Setup, das wir hier in einem Lauf nicht gewahrt haben.
Der Preis: MLX ist ein Apple-spezifisches Framework. Code, der in MLX geschrieben ist, läuft nicht auf NVIDIA-Karten und nicht auf AMD-Hardware. Wer Cross-Platform-Code schreibt, bleibt bei PyTorch. Wer auf einem Mac arbeitet und Performance braucht, sollte sich MLX anschauen.
Was nicht in der MLX-Version ist (und auch nicht trivial wird): Multi-GPU, weil MLX vorerst nur eine GPU pro Mac unterstützt; Distributed Training, weil das nicht zum Design gehört; und Flash-Attention, weil Apple seine eigenen Memory-Effizienz-Tricks im Compiler implementiert. Das wird vermutlich kommen, ist aber Stand heute (Mai 2026) noch nicht da.
Die beiden Skripte koexistieren bewusst. Wer auf Linux/CUDA arbeitet, nimmt build_basemodel.py. Wer auf einem Mac trainiert, sollte build_basemodel_mlx.py ausprobieren. Beide produzieren das gleiche Modell, sie nutzen nur verschiedene Hardware-Pfade, um es zu erreichen.
Installation der MLX-Variante:
uv sync --extra mlx
uv run build_basemodel_mlx.py --config small
mlx ist als optional dependency in pyproject.toml markiert — Linux-User installieren das nicht, weil es dort schlicht nicht verfügbar ist.
Mini-SFT — vom Basismodell zum (sehr kleinen) Assistenten
In Artikel 8 haben wir gesehen, dass aus einem Basismodell durch SFT (Supervised Fine-Tuning) ein Assistent wird. Das probieren wir hier en miniature aus, mit zehn Frage-Antwort-Paaren über Shakespeare, fünfmal repliziert auf 50 Trainings-Beispiele. Das ist ridikül wenig — produktive Modelle nutzen Hunderttausende —, reicht aber, um den Mechanismus zu zeigen.
Das Skript heißt sft_demo.py und lebt neben build_basemodel.py. Der wichtige Trick: der Loss wird nur über die Antwort-Tokens berechnet, nicht über die Frage:
def build_sft_batch(pairs, block_size, device):
inputs, targets = [], []
for question, answer in pairs:
prompt, full = format_chat(question, answer)
prompt_ids = encode(prompt)
full_ids = encode(full)
x = full_ids[:-1]
y = full_ids[1:]
prompt_len = len(prompt_ids) - 1
y = [-1] * prompt_len + y[prompt_len:] # Frage-Tokens werden ignoriert
...
return torch.tensor(inputs), torch.tensor(targets)
-1 als Target bedeutet ignore_index=-1 in cross_entropy — diese Positionen gehen nicht in den Gradient ein. Das Modell lernt also: „bei dieser Frage produziere diese Antwort", nicht „wiederhole die Frage und produziere dann die Antwort".
Output vor SFT (Basismodell small_best.pt auf Prompt im ChatML-Format, Frage „Who is Romeo?"):
<|system|>You are a helpful assistant trained on Shakespeare.<|end|>
<|user|>Who is Romeo?<|end|>
<|assistant|>rocket tubesossus simulation Morning tubes clothing Unknown HY
labelled disco needle Vaj tapes Clintons proceeds Tammy Tammy ), Vaj Vajroo
tubes inventor Borehens Lover Tropical Sentinel chall Clintons IranutanFI
imony sailHi Shepherdaminsdirection cytokanchester traged electing established
Dream chop dram InnovHaw Zone crude innovations LincolnolveFI hust plasteramins
anything tubesenabled Clintons Clintonsselection theme organis bride simulation
), misunder�TV Clintons fif dan Brigbringing dolphins tubes
Reines Rauschen. Das Basismodell hat die Spezialtokens (<|system|>, <|user|>, <|assistant|>, <|end|>) nie im Training gesehen — sie kommen in TinyShakespeare nicht vor. Es kennt sie nur als seltene IDs aus dem r50k_base-Vokabular, hat aber keine Vorstellung davon, was nach ihnen kommen soll. Folge: das Modell rät frei aus dem ganzen Vokabular und produziert Internet-Tokens (Clinton, Tammy, Iran, Lincoln), die mit Shakespeare nichts zu tun haben. Genau deshalb braucht es überhaupt einen SFT-Schritt: dem Modell beibringen, dass nach <|assistant|> eine Antwort kommt.
Output nach 5 Epochen SFT (small_sft.pt, gleicher Prompt):
<|system|>You are a helpful assistant trained on Shakespeare.<|end|>
<|user|>Who is Romeo?<|end|>
<|assistant|> EDWARD:
At AntigonAway'd a brave fellow for a woman's nose chafr'd a parlornication
Will hangman by Saint Paulina, a woman in his face?
Was ever too cold foolery buildeth in his head?
LADYORK:
And was his own?
GLOUCESTER:
The king by
Das Modell hat gelernt, dass nach <|assistant|> Text kommt — aber nicht welcher Text. Es fällt zurück in seinen Pretraining-Modus und generiert Pseudo-Shakespeare-Dialoge mit Sprechern aus den Königsdramen (Edward, Gloucester, Lady York), die mit der Frage nach Romeo nichts zu tun haben. Der QA-Mapping-Effekt, den richtiges SFT erzeugt — Frage rein, passende Antwort raus —, ist mit 50 Beispielen schlicht nicht erreichbar. Das Modell ist nicht ein nützlicher Assistent geworden. Es ist nicht einmal ein Papagei der Trainingsfragen. Es ist eine Demonstration, dass die SFT-Mechanik etwas ändert (Übergang von Rauschen zu kohärentem Text), aber dass der eigentliche Effekt — Befolgen von Anweisungen — Größenordnungen mehr Daten braucht. Wer ernsthaft fine-tunen will: größeres Basismodell, Tausende statt Hunderte Beispiele, und idealerweise einen DPO- oder RLHF-Schritt nach dem SFT (siehe Artikel 8).
Was funktioniert, was nicht
lal funktioniert in dem Sinn, dass das Skript läuft, der Loss konvergiert und am Ende lesbarer Pseudo-Shakespeare herauskommt. Was es nicht macht:
- Keine Argumentation. Das Modell — selbst in der
lal-Config mit 120M Parametern — hat 1 MB Trainingsdaten gesehen, das reicht für Stil, nicht für Inhalt. Wer fragt „wie spät ist es?" bekommt keine Antwort, sondern eine elisabethanisch klingende Verlegenheit. - Keine Fakten. Das Modell weiß nicht, dass Romeo zu den Montagues gehört — wir haben es ihm im SFT-Schritt zwar zehnmal beigebracht, aber 50 Beispiele reichen nicht einmal für Auswendiglernen, geschweige denn für Wissen. Bei jeder Frage halluziniert es.
- Kein Multi-Turn. Wir haben kein dediziertes Multi-Turn-Trainingssetup, also wird das Modell bei einer zweiten User-Message verwirrt.
- Kein RLHF, kein DPO, kein Constitutional AI. Die Sicherheits- und Hilfsbereitschafts-Ebene aus Artikel 8 ist hier nicht implementiert. Wer dem Modell beibringen wollte, schädliche Inhalte abzulehnen — keine Chance, nicht in diesem Maßstab.
Das ist auch nicht der Anspruch. lal ist ein didaktisches Modell. Es zeigt, wie alle Bausteine zusammenkommen, und es zeigt sehr klar, warum die echten Modelle so groß sind. Ein 120M-Parameter-Modell ist gerade groß genug, um Form zu lernen. Inhalt fängt irgendwo bei mehreren Milliarden Parametern und einigen Hundert Gigabyte Trainingstext an.
Wie es weitergeht
Wer jetzt weiterdenken will, hat ein paar gute Anlaufstellen. Karpathys nanoGPT ist die direkte Inspiration für diesen Bonus-Artikel — produktionsnäher, mit Multi-GPU-Support und besseren Defaults. llm.c ist Karpathys Versuch, dasselbe in reinem C zu schreiben, was schneller ist und keine PyTorch-Abhängigkeit braucht. HuggingFace TRL ist die Library, mit der man echtes RLHF/DPO/SFT auf größeren Modellen macht. Llama-Factory und Axolotl sind höher abstrahierte Frameworks für Fine-Tuning.
Wer nicht selbst trainieren, sondern lokal ein gutes kleines Modell laufen lassen will, kommt mit Ollama oder LM Studio plus Llama 3.2 oder Qwen 3.5/3.6 deutlich weiter als mit allem, was wir hier gebaut haben.
Aber das war auch nicht das Ziel. Das Ziel war, einmal von ganz unten nach ganz oben zu gehen — von der Token-ID bis zum generierten Shakespeare-Vers — ohne dass auf dem Weg etwas Magisches passiert. Wenn das funktioniert hat, wenn build_basemodel.py jetzt nicht mehr aussieht wie eine Black Box, sondern wie ein paar hundert Zeilen lesbarer Code, dann hat das Bonus-Kapitel seinen Zweck erfüllt.
„Father, the funny thing is, I am better than you." — Lal, Star Trek: TNG, S3E16 „The Offspring"
Bei einem 120M-Parameter-Modell auf TinyShakespeare ist diese Erwartung allerdings — wie schon im README erwähnt — überzogen. Lal in der Serie hält 36 Stunden, dann bricht ihre positronische Matrix unter ihren eigenen Emotionen zusammen. Unsere Lal überlebt etwas länger, wird dafür nie etwas Eigenes sagen. Die Brücke zwischen beiden ist genau die Frage, die in der Geschichte aller LLMs immer wieder hochkommt: was passiert, wenn wir das Ding größer machen, viel größer? Die ersten paar Antworten kennen wir aus den letzten zwei Jahren. Die nächsten paar werden interessant.
Quellen
- Repository: codeberg.org/rotecodefraktion/lal
- Karpathy, Andrej (2022). nanoGPT. github.com/karpathy/nanoGPT.
- Karpathy, Andrej (2024). llm.c. github.com/karpathy/llm.c.
- OpenAI (2019). GPT-2: Better Language Models and Their Implications. openai.com/research/better-language-models.
- Star Trek: The Next Generation, „The Offspring", Staffel 3 Episode 16, 1990.