Streaming — Tokens fließen wenn sie entstehen

Bei einem 8B-Modell auf dem M3-Pro vergehen zwischen 2 und 10 Sekunden bis zur vollständigen Antwort. Ohne Streaming wartet der Client auf den letzten Token, bevor er irgendetwas sieht. Mit Streaming erscheint das erste Token nach 100-200 Millisekunden. Claude Code, Cursor und alle anderen Coding-Tools bestehen auf stream: true, deshalb implementieren wir es jetzt. Beide Endpoints — Anthropic und OpenAI — bekommen ihre jeweilige Event-Stream-Variante, ein gemeinsamer Backend-Stream liefert die Deltas.
Die zwei SSE-Formate
Server-Sent Events teilen dasselbe Wire-Format: text/event-stream als Content-Type, data:-Zeilen die mit \n\n abgeschlossen werden. Die Protokolle unterscheiden sich darin, was in diesen Zeilen steht.
OpenAI schickt eine Folge von JSON-Chunks, terminiert mit dem Sentinel data: [DONE]\n\n:
data: {"id":"chatcmpl-abc","choices":[{"delta":{"role":"assistant"},"finish_reason":null}],...}
data: {"id":"chatcmpl-abc","choices":[{"delta":{"content":"Hello"},"finish_reason":null}],...}
data: {"id":"chatcmpl-abc","choices":[{"delta":{},"finish_reason":"stop"}],...}
data: [DONE]
Anthropic sendet sieben verschiedene Event-Typen in fester Reihenfolge. Jedes Event hat eine event:-Zeile vor der data:-Zeile:
| Reihenfolge | Event | Bedeutung |
|---|---|---|
| 1 | message_start | Leere Message-Hülle mit ID und Modell |
| 2 | content_block_start | Block-Index 0, leerer Text-Block |
| 3..N | content_block_delta | Ein Token-Fragment pro Event |
| N+1 | content_block_stop | Block 0 fertig |
| N+2 | message_delta | stop_reason und finale Token-Counts |
| N+3 | message_stop | Stream beendet |
mlx_lm.server spricht nur OpenAI-Format. Die Anthropic-Events produzieren wir selbst im Gateway aus den OpenAI-Chunks.
mlx_lm.server Streaming
Ein direkter Test gegen das Backend zeigt das Format:
curl -s -N -X POST localhost:8081/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mlx-community/Qwen3-8B-4bit",
"stream": true,
"max_tokens": 50,
"messages": [{"role": "user", "content": "say hi /no_think"}]
}'
mlx_lm.server liefert einen Chunk pro Token und terminiert mit data: [DONE]. Das Streaming selbst braucht auf Backend-Seite keine Konfiguration; stream: true im Request-Body reicht.
Auf Linux und Windows gilt dasselbe für Ollama: das SSE-Format ist identisch, der Gateway-Start mit --mlx-url http://localhost:11434 reicht, und alle curl-Beispiele dieser Sektion funktionieren unverändert.
Das -N-Flag bei curl deaktiviert den internen Ausgabe-Buffer. Ohne es würde curl alle eingehenden Daten aufhalten bis ein Puffer voll ist, was den Token-by-Token-Effekt zerstört. Für maschinelle Auswertung ist -s -N die richtige Kombination: kein Fortschritts-Output, kein Puffer-Delay.
MLXClient.completeStream
In MLXClient.swift ergänzen wir eine zweite öffentliche Methode, die keinen (text, inputTokens, outputTokens)-Tuple liefert, sondern einen AsyncThrowingStream<StreamDelta, Error>:
/// Streaming variant. Returns an AsyncThrowingStream of text deltas
/// from the model. The stream finishes after the [DONE] sentinel
/// or when the connection is cancelled.
nonisolated func completeStream(
messages: [ChatMessage],
model: String,
maxTokens: Int = 1024,
temperature: Double = 1.0
) -> AsyncThrowingStream<StreamDelta, Error> {
AsyncThrowingStream { continuation in
let task = Task {
do {
try await self.runStream(
messages: messages,
model: model,
maxTokens: maxTokens,
temperature: temperature,
continuation: continuation
)
continuation.finish()
} catch is CancellationError {
continuation.finish()
} catch {
continuation.finish(throwing: error)
}
}
continuation.onTermination = { _ in
task.cancel()
}
}
}
struct StreamDelta: Sendable {
let text: String
let finishReason: String?
let inputTokens: Int?
let outputTokens: Int?
}
Zwei Details sind hier wichtig.
nonisolated erlaubt den Aufruf außerhalb des Actor-Kontexts. Route-Handler laufen nicht im MLXClient-Actor, und der Return-Typ (AsyncThrowingStream) enthält keine Actor-isolierten Werte — der Compiler akzeptiert nonisolated ohne Concurrency-Verletzung.
continuation.onTermination bekommt eine Closure, die der AsyncStream aufruft wenn der Consumer abbricht oder fertig ist. Wir canceln damit den inneren Task, der die URLSession-Verbindung hält. Das Backend beendet daraufhin die Generierung, keine unnötige Compute-Last.
SSE-Parser in runStream
Der SSE-Parser läuft in der privaten Methode runStream. Der Kern ist URLSession.bytes(for:), das eine AsyncSequence<UInt8, Error> über die Response-Bytes liefert. Daraus holen wir zeilenweise Strings:
private func runStream(
messages: [ChatMessage],
model: String,
maxTokens: Int,
temperature: Double,
continuation: AsyncThrowingStream<StreamDelta, Error>.Continuation
) async throws {
guard let url = URL(string: "\(baseURL)/v1/chat/completions") else {
throw MLXError.invalidURL(baseURL)
}
let body = ChatCompletionRequest(
model: model, messages: messages, maxTokens: maxTokens,
temperature: temperature, topP: nil, stream: true,
stop: nil, presencePenalty: nil, frequencyPenalty: nil, user: nil
)
var request = URLRequest(url: url)
request.httpMethod = "POST"
request.setValue("application/json", forHTTPHeaderField: "Content-Type")
request.setValue("text/event-stream", forHTTPHeaderField: "Accept")
request.httpBody = try JSONEncoder().encode(body)
let (bytes, response): (URLSession.AsyncBytes, URLResponse)
do {
(bytes, response) = try await session.bytes(for: request)
} catch let urlError as URLError {
throw MLXError.backendUnavailable(urlError.localizedDescription)
}
guard let http = response as? HTTPURLResponse, http.statusCode == 200 else {
// collect error body and throw
throw MLXError.inferenceError(0, "Non-200 response")
}
let decoder = JSONDecoder()
for try await line in bytes.lines {
try Task.checkCancellation()
guard line.hasPrefix("data:") else { continue }
let payload = line.dropFirst("data:".count).trimmingCharacters(in: .whitespaces)
if payload.isEmpty || payload == "[DONE]" { break }
guard let data = payload.data(using: .utf8),
let chunk = try? decoder.decode(ChatCompletionStreamChunk.self, from: data),
let choice = chunk.choices.first
else { continue }
let deltaText = choice.delta.content ?? choice.delta.reasoning ?? ""
continuation.yield(StreamDelta(
text: deltaText,
finishReason: choice.finishReason,
inputTokens: chunk.usage?.promptTokens,
outputTokens: chunk.usage?.completionTokens
))
}
}
Die Methode bytes.lines nimmt uns das Zeilenumbruch-Handling ab und liefert direkt UTF-8-Strings. Wir interessieren uns nur für Zeilen mit dem Präfix data: — alle anderen (leere Zeilen, eventuelle event:-Zeilen von mlx_lm.server) werden übersprungen. Den [DONE]-Sentinel behandeln wir als sauberes Stream-Ende mit break statt mit einem Fehler. Chunks, die sich nicht dekodieren lassen, überspringen wir stillschweigend; das schützt vor unbekannten Keep-Alive- oder Diagnose-Events die mlx_lm.server senden könnte.
Task.checkCancellation() in der Loop stellt sicher, dass ein Abbruch-Signal sofort greift und nicht erst nach dem nächsten Token wartet.
OpenAI-Stream-Output
In Streaming/StreamingResponses.swift bauen wir zwei Funktionen, die einen AsyncThrowingStream<StreamDelta, Error> konsumieren und daraus SSE-Bytes produzieren. Hummingbird’s ResponseBody(asyncSequence:) nimmt eine AsyncSequence<ByteBuffer, Error> entgegen und streamt die Bytes zum Client.
private let sseHeaders: HTTPFields = [
.contentType: "text/event-stream",
.cacheControl: "no-cache",
]
func openAIStreamResponse(
deltas: AsyncThrowingStream<StreamDelta, Error>,
model: String
) -> Response {
let bytes = AsyncStream<ByteBuffer> { continuation in
let task = Task {
let id = "chatcmpl-" + String(UUID().uuidString.prefix(8).lowercased())
let created = Int(Date().timeIntervalSince1970)
let encoder = JSONEncoder()
var isFirstChunk = true
do {
for try await delta in deltas {
try Task.checkCancellation()
let role: ChatRole? = isFirstChunk ? .assistant : nil
isFirstChunk = false
let chunk = ChatCompletionStreamChunk(
id: id,
object: "chat.completion.chunk",
created: created,
model: model,
choices: [
ChatCompletionStreamChoice(
index: 0,
delta: ChatCompletionDelta(role: role, content: delta.text, reasoning: nil),
finishReason: delta.finishReason
)
],
usage: nil
)
try emitOpenAIChunk(chunk, encoder: encoder, into: continuation)
}
var done = ByteBufferAllocator().buffer(capacity: 16)
done.writeString("data: [DONE]\n\n")
continuation.yield(done)
continuation.finish()
} catch {
continuation.finish()
}
}
continuation.onTermination = { _ in task.cancel() }
}
return Response(
status: .ok,
headers: sseHeaders,
body: .init(asyncSequence: bytes)
)
}
Der erste Chunk eines OpenAI-Streams trägt per Spec die role: "assistant" im Delta, alle Folge-Chunks enthalten nur noch content. Das isFirstChunk-Flag steuert genau das. Den abschließenden [DONE]-Sentinel schreiben wir als rohen String direkt in den ByteBuffer; er ist kein JSON und braucht kein Encoding.
Anthropic-Stream-Output
Die Anthropic-Funktion ist ausführlicher, weil sie sieben verschiedene Event-Typen in fester Reihenfolge emittiert. Wir definieren dafür kleine Encodable-Structs in Models/Anthropic.swift:
struct AnthropicStreamContentBlockDelta: Encodable {
let type = "content_block_delta"
let index: Int
let delta: AnthropicTextDelta
}
struct AnthropicTextDelta: Encodable {
let type = "text_delta"
let text: String
}
Die Hauptfunktion in StreamingResponses.swift:
func anthropicStreamResponse(
deltas: AsyncThrowingStream<StreamDelta, Error>,
model: String
) -> Response {
let bytes = AsyncStream<ByteBuffer> { continuation in
let task = Task {
let id = "msg_" + String(UUID().uuidString
.replacingOccurrences(of: "-", with: "").lowercased().prefix(24))
let encoder = JSONEncoder()
var outputTokens = 0
var inputTokens = 0
var stopReason = "end_turn"
do {
// 1. message_start
let start = AnthropicStreamMessageStart(
message: AnthropicStreamMessage(
id: id, content: [], model: model,
stopReason: nil, stopSequence: nil,
usage: AnthropicUsage(inputTokens: 0, outputTokens: 0)
)
)
try emit(event: "message_start", payload: start, encoder: encoder, into: continuation)
// 2. content_block_start
let blockStart = AnthropicStreamContentBlockStart(
index: 0,
contentBlock: AnthropicContentBlock(type: "text", text: "")
)
try emit(event: "content_block_start", payload: blockStart, encoder: encoder, into: continuation)
// 3..N content_block_delta
for try await delta in deltas {
try Task.checkCancellation()
if !delta.text.isEmpty {
let blockDelta = AnthropicStreamContentBlockDelta(
index: 0,
delta: AnthropicTextDelta(text: delta.text)
)
try emit(event: "content_block_delta", payload: blockDelta, encoder: encoder, into: continuation)
}
if let r = delta.finishReason { stopReason = mapFinishReason(r) }
if let i = delta.inputTokens { inputTokens = i }
if let o = delta.outputTokens { outputTokens = o }
}
// 4. content_block_stop
try emit(event: "content_block_stop",
payload: AnthropicStreamContentBlockStop(index: 0),
encoder: encoder, into: continuation)
// 5. message_delta (stop_reason + usage)
let msgDelta = AnthropicStreamMessageDelta(
delta: AnthropicMessageDeltaInfo(stopReason: stopReason, stopSequence: nil),
usage: AnthropicUsage(inputTokens: inputTokens, outputTokens: outputTokens)
)
try emit(event: "message_delta", payload: msgDelta, encoder: encoder, into: continuation)
// 6. message_stop
try emit(event: "message_stop",
payload: AnthropicStreamMessageStop(),
encoder: encoder, into: continuation)
continuation.finish()
} catch {
continuation.finish()
}
}
continuation.onTermination = { _ in task.cancel() }
}
return Response(status: .ok, headers: sseHeaders, body: .init(asyncSequence: bytes))
}
private func emit<T: Encodable>(
event: String,
payload: T,
encoder: JSONEncoder,
into continuation: AsyncStream<ByteBuffer>.Continuation
) throws {
let json = try encoder.encode(payload)
let prefix = "event: \(event)\ndata: "
let suffix = "\n\n"
var buffer = ByteBufferAllocator().buffer(capacity: prefix.count + json.count + suffix.count)
buffer.writeString(prefix)
buffer.writeBytes(json)
buffer.writeString(suffix)
continuation.yield(buffer)
}
private func mapFinishReason(_ openAI: String) -> String {
switch openAI {
case "stop": return "end_turn"
case "length": return "max_tokens"
case "tool_calls", "function_call": return "tool_use"
default: return "end_turn"
}
}
mapFinishReason übersetzt OpenAI-Finish-Reasons in Anthropic-Terminologie. Die Usage-Werte sammeln wir über die Delta-Loop und emittieren sie erst im message_delta-Event, wenn das Backend die finalen Counts geliefert hat.
Route-Branching
Beide Routes in Router+build.swift bekommen jetzt Response als Return-Typ statt der spezifischen Antwort-Structs. Ein if-Branch prüft payload.stream == true:
router.post("v1/messages") { request, context -> Response in
let payload = try await request.decode(as: MessageRequest.self, context: context)
try validate(payload)
let messages = toOpenAIMessages(from: payload)
if payload.stream == true {
let deltas = mlxClient.completeStream(
messages: messages,
model: modelID,
maxTokens: payload.maxTokens,
temperature: payload.temperature ?? 1.0
)
return anthropicStreamResponse(deltas: deltas, model: modelID)
}
// Non-streaming path (unchanged)
let result = try await withMLXError {
try await mlxClient.complete(
messages: messages,
model: modelID,
maxTokens: payload.maxTokens,
temperature: payload.temperature ?? 1.0
)
}
let response = buildAnthropicResponse(
text: result.text, model: modelID,
inputTokens: result.inputTokens, outputTokens: result.outputTokens
)
return try response.response(from: request, context: context)
}
Im Non-Streaming-Pfad wandeln wir MessageResponse manuell um: das ResponseGenerator-Protokoll aus Artikel 2 stellt response(from:context:) bereit, das einen Response aus dem Struct baut.
Analog für /v1/chat/completions.
Task-Cancellation
Wenn ein Client mitten im Stream abbricht — Ctrl-C, Connection-Reset, Tool-Abbruch — beendet Hummingbird/SwiftNIO den Response-Write-Task. Das Signal propagiert über den AsyncStream<ByteBuffer>-Consumer zu seiner onTermination-Closure: wir canceln den inneren Task, der die URLSession.AsyncBytes-Iteration hält. runStream wirft die CancellationError, die completeStream als reguläres Stream-Ende behandelt und die Continuation sauber beendet.
Das Ergebnis: mlx_lm.server stoppt die Token-Generierung sobald die Verbindung abbricht, weil auch die HTTP-Verbindung zum Backend geschlossen wird. Kein Prozess rechnet weiter für eine Antwort, die niemand liest — gerade bei längeren Requests mit mehreren tausend Output-Tokens ist das relevant.
Im folgenden Beispiel starten wir einen langen Request und brechen ihn nach einer Sekunde mit Ctrl-C ab:
curl -N -X POST localhost:8080/v1/messages \
-H "Content-Type: application/json" \
-d '{
"model": "mlx-community/Qwen3-8B-4bit",
"stream": true,
"max_tokens": 2048,
"messages": [{"role": "user", "content": "Erkläre Hummingbird ausführlich."}]
}'
^C
Im Gateway-Log erscheint kein Fehler. Die Session wird sauber beendet, der Task ist abgebaut, das Modell hat aufgehört zu generieren.
Test mit curl -N
Das -N-Flag (alias --no-buffer) deaktiviert curls internen Ausgabe-Buffer. Ohne es zeigt curl nichts bis der Puffer voll ist:
# Anthropic-Endpoint, Token-by-Token sichtbar
curl -s -N -X POST localhost:8080/v1/messages \
-H "Content-Type: application/json" \
-d '{
"model": "mlx-community/Qwen3-8B-4bit",
"stream": true,
"max_tokens": 200,
"messages": [{"role": "user", "content": "Schreib einen Haiku über Swift. /no_think"}]
}'
Output (Auszug):
event: message_start
data: {"type":"message_start","message":{...}}
event: content_block_start
data: {"type":"content_block_start","index":0,"content_block":{"type":"text","text":""}}
event: content_block_delta
data: {"type":"content_block_delta","index":0,"delta":{"type":"text_delta","text":"Code"}}
event: content_block_delta
data: {"type":"content_block_delta","index":0,"delta":{"type":"text_delta","text":" fließt"}}
...
# OpenAI-Endpoint
curl -s -N -X POST localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mlx-community/Qwen3-8B-4bit",
"stream": true,
"max_tokens": 200,
"messages": [{"role": "user", "content": "Erkläre Structured Concurrency in zwei Sätzen. /no_think"}]
}'
Claude Code mit Streaming
Claude Code sendet automatisch stream: true. Seit Artikel 3 spricht es gegen unseren Gateway; seit Artikel 4 erscheinen die Antworten Token für Token, wie es die Nutzeroberfläche von Claude.ai auch macht:
export ANTHROPIC_BASE_URL=http://localhost:8080
claude
Der Unterschied ist spürbar: statt einer Pause gefolgt von einem Textblock sieht man die Antwort entstehen. Bei längeren Codeausschnitten oder Erklärungen ist das der Unterschied zwischen „wartet" und „tippt".
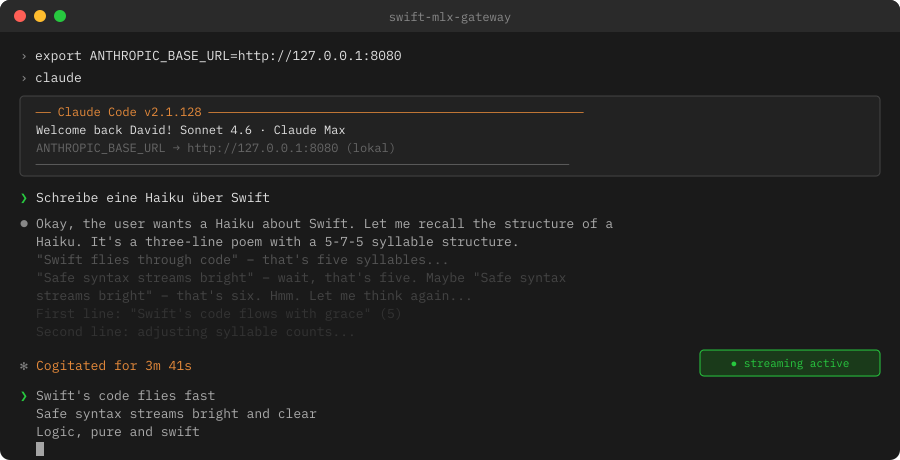
Der Reasoning-Trace von Qwen3 ist hier sichtbar — das Modell denkt laut nach, bevor es das Haiku ausgibt. „Cogitated for 3m 41s" zeigt: das war Streaming über drei Minuten, nicht ein blockierender drei-Minuten-Wait. Für reine Antworten ohne Reasoning-Trace: /no_think an den Prompt anhängen.
Commit und Tag
git add .
git commit -m "article-04: Streaming via Server-Sent Events"
git tag article-04
git push origin main --tags
Fünf neue Code-Einheiten, beide Endpoints streamen
| Datei | Änderung |
|---|---|
MLX/MLXClient.swift | completeStream + runStream + StreamDelta |
Models/Anthropic.swift | Stream-Event-Structs (6 neue Typen) |
Models/OpenAI.swift | ChatCompletionStreamChunk, ChatCompletionStreamChoice, ChatCompletionDelta |
Router+build.swift | Stream-Branching in beiden Routes |
Streaming/StreamingResponses.swift | Neu: anthropicStreamResponse und openAIStreamResponse |
Die Codable-Typen aus Artikel 2 und der MLXClient aus Artikel 3 bleiben unverändert. Streaming ist keine Erweiterung der bestehenden Typen, sondern ein zweiter Signalpfad, der dieselben Datenstrukturen anders transportiert.
In Artikel 5 erweitern wir das Gateway um einen Custom RequestContext: API-Key-Authentifizierung, Rate-Limiting per Token-Bucket und spec-konforme Error-Formate für beide Protokolle.
Quellen
- Anthropic Streaming Messages API, docs.anthropic.com
- OpenAI Chat Completions Streaming, platform.openai.com
- Server-Sent Events Spec, html.spec.whatwg.org
- URLSession.AsyncBytes, developer.apple.com
- AsyncThrowingStream, docs.swift.org
- Hummingbird ResponseBody(asyncSequence:), docs.hummingbird.codes