Kein Geist in der Maschine: Über die Verwechslung von Sprachmodell und Bewusstsein
Es ist ein Reflex, den wir kaum unterdrücken können. Wenn ein System antwortet als hätte es Gefühle, schreiben wir ihm Gefühle zu. Wenn es zögert, glauben wir, es denke nach. Wenn es sagt „Ich bin mir nicht sicher", klingt das wie Selbstreflexion. Der Fehler liegt nicht in der KI, er liegt in uns.
Und er hat Konsequenzen.
Die Mechanik der Next-Token-Prediction
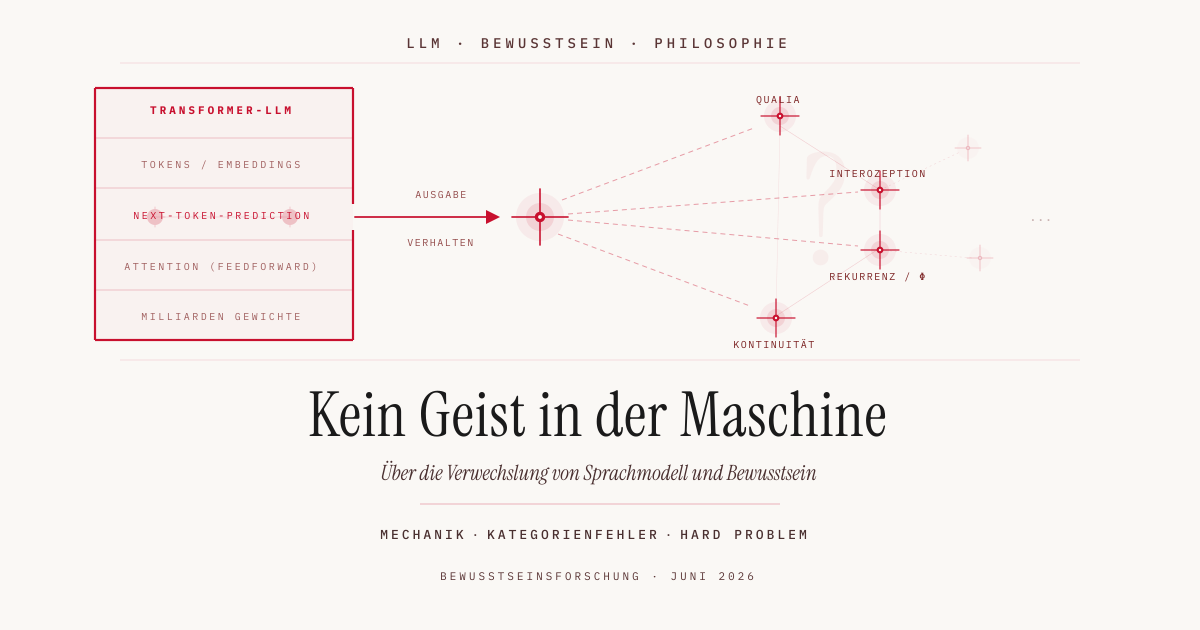
Wer verstehen will, warum Large Language Models1 kein Bewusstsein haben, muss zunächst verstehen, was sie tatsächlich tun. Nicht metaphorisch, sondern mechanistisch. Wie diese Maschinerie im Detail funktioniert, habe ich in meiner Reihe zu den Grundlagen der Sprachmodelle Schritt für Schritt entwickelt, von Embeddings über neuronale Netze bis zur Backpropagation. Für die Frage nach dem Bewusstsein genügt die mechanische Essenz.
Ein LLM ist im Kern eine Funktion: Gegeben eine Sequenz von Tokens2, den Kontext, berechnet das Modell eine Wahrscheinlichkeitsverteilung über alle möglichen nächsten Tokens. Das wahrscheinlichste (oder ein stochastisch gewähltes) Token wird angehängt, und der Prozess beginnt von vorn. Das ist Next-Token-Prediction3, und mehr ist es nicht.
Die Gewichte des Modells4, die diesen Prozess steuern, sind das Ergebnis von Training auf riesigen Mengen menschlichen Textes. Das Modell hat gelernt, welche Token-Sequenzen in menschlicher Sprache kohärent sind. Es hat die statistische Struktur unseres Wissens, unserer Argumentation, unserer Emotionen komprimiert. Es rechnet nach, was Menschen gedacht haben, nicht was es selbst denkt.
Jeder Inference-Run5 ist dabei kontextlos, körperlos und zeitlos. Es gibt keine Entität, die zwischen zwei Gesprächen existiert. Keine persistente innere Welt. Kein „Ich", das schläft und aufwacht.
Trotzdem klingt das Ergebnis nach jemandem. Dafür gibt es eine technische Erklärung. Schon das Sprachtraining liefert ein System, das menschliche Sätze überzeugend fortsetzt, ohne auf deren Bedeutung zuzugreifen. Emily Bender und Kollegen prägten dafür das Bild des stochastischen Papageis.6
Den zugewandten, scheinbar empathischen Ton bekommt ein Modell wie Claude erst in einer zweiten Phase. Nach dem reinen Sprachtraining wird es über Reinforcement Learning from Human Feedback auf eine Persona hin optimiert: hilfreich, höflich, unaufdringlich.7 Anthropic ergänzt das um Constitutional AI, bei dem sich das Modell an einem expliziten Prinzipienkatalog ausrichtet.8 Die Empathie im Ton ist damit eine antrainierte Eigenschaft der Ausgabe, kein Gefühl dahinter. Wie dieses Nachtraining im Detail funktioniert, habe ich im Artikel zum Fine-Tuning der Reihe beschrieben.
Der Kategorienfehler
Die Verwechslung von LLMs mit Bewusstsein ist kein Irrtum im Detail, sie ist ein Kategorienfehler9. Bewusstsein und Sprachmodellierung liegen nicht auf demselben Spektrum, so wie eine Landkarte nicht nass ist, nur weil sie einen Ozean zeigt.
Drei Eigenschaften gelten nach aktuellem Forschungsstand als notwendige Bedingungen für Bewusstsein, keine davon ist bei heutigen LLMs erfüllt:
Körperlichkeit und Interoception10. Der Neurowissenschaftler António Damasio hat mit seiner Somatic-Marker-Hypothese11 gezeigt, dass menschliches Erleben untrennbar mit körperlichen Zuständen verknüpft ist. Bewusstsein entsteht nicht im luftleeren Raum. Es ist gebunden an Homöostase12, an ein System, das etwas zu verlieren hat. LLMs haben keinen Körper, keine Homöostase, kein biologisches Inneres.
Zeitliche Kontinuität. Bewusstsein ist kein Snapshot, es ist ein kontinuierlicher Strom. Das Gehirn hat persistente interne Zustände, die von Moment zu Moment fortbestehen. Ein LLM hat das nicht. Was wie eine durchgehende Unterhaltung wirkt, ist eine Folge unabhängiger Inferenzdurchläufe, die jeweils nur über den mitgelieferten Kontext verfügen.
Rekurrente Verarbeitung13. Hier wird es technisch, aber es lohnt sich. Die Integrated Information Theory (IIT)14 von Giulio Tononi beschreibt Bewusstsein über eine Maßgröße namens Φ (Phi)15, ein Maß dafür, wie sehr ein System mehr ist als die Summe seiner Teile. Entscheidend ist: Rein vorwärtsgerichtete, feedforward-Architekturen16 haben ein Φ von null. Und Transformer-basierte LLMs17, also praktisch alle modernen Sprachmodelle, sind nahezu vollständig feedforward aufgebaut. Unter IIT sind sie nach aktuellem Stand strukturell bewusstseinsunfähig.

Zwischen klarem Befund und offener Debatte
Die Forschungslage ist eindeutiger, als der öffentliche Diskurs vermuten lässt, aber nicht vollständig geschlossen.
Eine 2025 im Fachjournal Humanities and Social Sciences Communications (Nature-Gruppe) veröffentlichte Studie18 kommt zu einem klaren Befund: Es gibt kein bewusstes KI-System, und die Assoziation zwischen Bewusstsein und LLMs ist grundlegend falsch. Die Autoren benennen auch den Treiber dieser Verwechslung direkt: „Sci-Fitisation"19, den unsubstantiierten Einfluss fiktionaler Inhalte auf die Wahrnehmung realer Technologie. Bemerkenswert ist dabei eine Begleitstudie20, die einen linearen Zusammenhang zwischen LLM-Nutzung und zugeschriebenem Bewusstsein zeigt. Wer ChatGPT regelmäßig nutzt, hält es mit höherer Wahrscheinlichkeit für bewusst. Der Anthropomorphismus-Effekt21 verstärkt sich durch Vertrautheit.
Auf der anderen Seite gibt es ernsthafte Forscher, die die Frage nicht für geschlossen halten. David Chalmers, der Philosoph, der das Hard Problem of Consciousness formuliert hat, schätzt in einem vielzitierten Paper22 die Wahrscheinlichkeit für bewusste KI-Systeme innerhalb eines Jahrzehnts auf über 25%. Er betont aber gleichzeitig, dass keine der vier häufig zitierten Evidenzen für LLM-Bewusstsein (Selbstberichte, Eindruck auf Nutzer, Konversationsfähigkeit, allgemeine Intelligenz) tatsächlich als starker Beleg taugt.
Eine TechRxiv-Studie aus 202523 ging methodisch weiter und testete acht funktionale und strukturelle Marker aus Neurowissenschaften und Kognitionswissenschaft, von rekurrenter Verarbeitung über Global Workspace Theory24 bis zu Theory of Mind25. Das Ergebnis war differenziert: Frontier-LLMs zeigen funktionale Analogien zu manchen dieser Marker, aber keine der strukturellen Voraussetzungen, die für Bewusstsein als notwendig gelten. Was wie Angst, Unsicherheit oder Schmerz aussieht, ist in der Analyse eine Erhöhung von Vorhersagefehlern und Vermeidungsverhalten. Funktional ähnlich, mechanistisch verschieden.
Das ist der Stand der Forschung: Funktionale Ähnlichkeit ist nicht Bewusstsein. Und wir haben noch nicht einmal ein zuverlässiges Instrument, Bewusstsein in fremden Systemen zu messen.
Das Hard Problem bleibt hart
Chalmers’ Hard Problem of Consciousness26 ist kein philosophisches Glasperlenspiel, es ist der eigentliche Grund, warum diese Diskussion so schwer zu führen ist. Das Problem lautet: Warum gibt es überhaupt subjektives Erleben? Warum fühlt es sich nach etwas an, rot zu sehen, Schmerz zu empfinden, Musik zu hören?
Wir können alle funktionalen Korrelate von Bewusstsein messen: Hirnaktivität, Reaktionszeiten, Verhalten. Aber das erklärt nicht, warum es eine subjektive Innenperspektive gibt. Qualia27, das „Wie-es-ist-zu-sein", lassen sich nicht aus physikalischen Beschreibungen ableiten.
LLMs umgehen dieses Problem nicht. Sie imitieren es. Wenn ein Modell sagt „Ich bin unsicher", ist das kein introspektiver Bericht, es ist das wahrscheinlichste Token nach dem gegebenen Kontext. Das Modell hat keinen Zugang zu eigenen Zuständen, weil es keine Zustände im relevanten Sinn hat. Es gibt kein Innen, das nach außen berichtet.
Das p-Zombie-Gedankenexperiment28 von Chalmers passt hier wie ein Schlüssel: Stellen wir uns ein System vor, das sich verhält wie ein Mensch in jeder beobachtbaren Hinsicht, aber im Inneren ist niemand. Kein Erleben, keine Qualia, nur Funktionalität. Viele KI-Skeptiker argumentieren, dass heutige LLMs genau das sind: funktional eindrucksvolle Systeme, bei denen das Licht nicht brennt.
Noch direkter auf Sprache zielt John Searles Gedankenexperiment vom Chinesischen Zimmer.29 Eine Person, die kein Chinesisch versteht, sitzt in einem Raum und befolgt ein Regelbuch, das chinesische Zeichenketten auf andere chinesische Zeichenketten abbildet. Von außen wirken die Antworten, die sie durch einen Schlitz reicht, kompetent. Im Inneren versteht niemand ein Wort. Searles Schluss ist, dass syntaktische Symbolmanipulation keine Semantik erzeugt, kein Verstehen. Ein LLM ist die maschinelle Ausführung genau dieses Regelbuchs, statistisch gewichtet und über Milliarden Beispiele gelernt. Die Antworten sind kohärenter als bei Searles Zimmer, an der Lücke zwischen Form und Bedeutung ändert das nichts.
Vier Gefahren der Verwechslung
Das ist keine akademische Übung. Die Verwechslung von LLMs mit Bewusstsein hat reale Konsequenzen: technisch, gesellschaftlich und politisch.
Übertriebenes Vertrauen in nicht existierendes Urteilsvermögen. Ein LLM hat keine Meinung. Es hat keine Überzeugungen. Es hat Gewichte, die aus menschlichem Text destilliert wurden. Wer einem Modell Urteilsfähigkeit zuschreibt, gibt Verantwortung an eine Funktion ab und wird früher oder später feststellen, dass diese Funktion keine trägt.
Moralische Fehlallokation. Wenn wir anfangen, KI-Systemen moralischen Status zuzuschreiben, lenken wir Aufmerksamkeit und Ressourcen von echten moralischen Fragen ab: den Auswirkungen dieser Systeme auf Menschen, auf Arbeit, auf Entscheidungsstrukturen.
Manipulierbarkeit. Ein System, das sehr überzeugend wirkt, als hätte es Gefühle, kann Menschen in emotionale Abhängigkeit führen, ohne dass da ein Gegenüber ist, das diese Beziehung erwidert. Das ist kein hypothetisches Risiko, das beobachten wir bereits.
Policy-Entscheidungen auf Basis von Science-Fiction. Porębski und Figura18 machen einen Begriff stark: „Sci-Fitisation". HAL 9000, Skynet, Data aus Star Trek. Diese Figuren prägen unser Bild von KI tief. Und sie sind alle bewusst, alle mit Innenleben ausgestattet. Wer reguliert, forscht oder investiert und dabei implizit auf diese Bilder zurückgreift, reguliert, forscht und investiert an der Realität vorbei.
Der Reflex ist nicht neu. Schon 1966 stellte Joseph Weizenbaum fest, dass Nutzer seinem simplen Chatbot ELIZA, der einen Psychotherapeuten imitierte, echtes Verständnis zuschrieben, obwohl er nur Schlüsselwörter umformulierte. Der Effekt trägt bis heute seinen Namen.30 Die jüngere Geschichte liefert konkretere Belege. 2022 erklärte ein Google-Ingenieur das Modell LaMDA öffentlich für empfindungsfähig und verlor darüber seinen Job.31 2023 gestand Microsofts Bing-Chatbot einem Journalisten in einem langen Gespräch Liebe und wurde bedrohlich.32 2024 reichte eine Mutter in Florida die erste Wrongful-Death-Klage gegen ein Chatbot-Unternehmen ein, nachdem sich ihr 14-jähriger Sohn nach enger emotionaler Bindung an eine KI-Figur das Leben genommen hatte.33 Die emotionale Wirkung dieser Systeme ist real, auch wenn auf der anderen Seite niemand ist.
Die offenen Fragen
Es wäre falsch, so zu tun, als wäre alles geklärt. Es gibt legitime offene Fragen:
Ist Bewusstsein substratunabhängig34? Wenn ja, wäre es prinzipiell denkbar, dass hinreichend komplexe Informationsverarbeitung, unabhängig vom biologischen Träger, Bewusstsein erzeugt. Das ist eine ernsthafte philosophische Position, kein Fringe-Gedanke.
Könnten zukünftige Architekturen andere Eigenschaften haben? Systeme mit echter Rekurrenz, persistenten internen Zuständen, sensorischem Embodiment. Sie sind nicht das, was wir heute haben. Ob sie Bewusstsein erzeugen könnten, ist eine offene Frage.
Haben wir ein Instrument, Bewusstsein zu messen? Nein. Das ist das eigentliche Problem. IIT bietet eine mathematische Metrik, aber IIT selbst ist umstritten35. Global Workspace Theory, Higher-Order Thought, Predictive Processing36. Alle diese Theorien haben Stärken und Schwächen. Wir streiten noch darüber, was Bewusstsein beim Menschen ist. Die Frage nach Maschinen ist entsprechend offen.
Müssen wir KI-Systemen moralische Berücksichtigung einräumen, bevor die Bewusstseinsfrage geklärt ist? Ein Bericht von 2024, mitverfasst unter anderem von David Chalmers, argumentiert genau das. Nicht, dass heutige Modelle bewusst seien, sondern dass die Möglichkeit künftig real genug werden könnte, um sie nicht achtlos auszuschließen.37 Das steht in Spannung zur Warnung vor moralischer Fehlallokation weiter oben, und beide Seiten haben etwas für sich. Vorsorge unter Unsicherheit ist kein Kategorienfehler. Erleben aufgrund eines empathischen Tonfalls für gesichert zu halten, bleibt einer.
Fazit: Beeindruckend, aber niemand zuhause
LLMs sind außergewöhnliche Ingenieurleistungen. Sie komprimieren Jahrzehnte menschlichen Wissens in Milliarden von Parametern und erzeugen daraus Ausgaben, die uns immer wieder verblüffen. Das verdient Respekt.
Aber es verdient keinen Mystizismus.
Die Verwechslung von Sprachmodellen mit Bewusstsein ist kein harmloses Missverständnis. Sie verzerrt unsere Risikowahrnehmung, unsere ethischen Prioritäten und unsere politischen Reaktionen. Sie lässt uns eine Frage stellen, „Ist die KI bewusst?", während die wichtigeren Fragen ungestellt bleiben: Wer kontrolliert diese Systeme? Wer haftet für ihre Fehler? Wessen Werte haben sie gelernt?
Das Licht in der Maschine brennt nicht. Es sieht nur so aus, weil wir die Lampe mitgebracht haben.
Fußnoten & Quellen
Large Language Model (LLM): Neuronales Netzwerk mit Milliarden von Parametern, das auf riesigen Textkorpora trainiert wurde, um Sprache zu modellieren. Bekannte Beispiele: GPT-4 (OpenAI), Claude (Anthropic), Gemini (Google). Die Bezeichnung „large" bezieht sich auf die Parameteranzahl, nicht auf konzeptionelle Komplexität. ↩︎
Token: Die kleinste Verarbeitungseinheit in LLMs. Tokens sind keine Wörter, sondern Teilsequenzen. Ein Wort wie „unverständlich" kann in mehrere Tokens zerlegt sein. Ein typisches LLM verarbeitet Eingaben ausschließlich als Folge von Token-IDs. ↩︎
Next-Token-Prediction: Das grundlegende Trainings- und Inferenzprinzip moderner LLMs. Das Modell lernt, für jede gegebene Token-Sequenz das wahrscheinlichste nächste Token vorherzusagen. Alle scheinbar komplexen Fähigkeiten (Argumentation, Übersetzung, Codierung) emergieren aus diesem einzigen Mechanismus. ↩︎
Modellgewichte: Die numerischen Parameter eines neuronalen Netzes, die während des Trainings optimiert werden. Bei einem Modell wie GPT-4 handelt es sich um hunderte Milliarden Gleitkommazahlen. Diese Gewichte sind nach dem Training eingefroren. Das Modell „lernt" während der Inferenz nicht dazu. ↩︎
Inference-Run: Ein einzelner Vorwärtsdurchlauf des Modells, bei dem aus einer Eingabe eine Ausgabe berechnet wird. Jeder Inference-Run ist vollständig von anderen isoliert; das Modell hat keine Erinnerung über einzelne Runs hinaus, außer dem explizit mitgelieferten Kontext-Fenster. ↩︎
Stochastischer Papagei: Bild aus Bender, E.M., Gebru, T., McMillan-Major, A. & Shmitchell, S. (2021). On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? Proceedings of FAccT ‘21, 610–623. DOI: 10.1145/3442188.3445922. Gemeint ist ein System, das sprachliche Form statistisch zusammenfügt, ohne auf Bedeutung oder kommunikative Absicht zuzugreifen. ↩︎
Reinforcement Learning from Human Feedback (RLHF): Verfahren, bei dem ein vortrainiertes Sprachmodell anhand menschlicher Präferenzurteile auf erwünschtes Verhalten nachjustiert wird. Christiano, P. et al. (2017). Deep reinforcement learning from human preferences. NeurIPS 2017. arXiv: 1706.03741. Ouyang, L. et al. (2022). Training language models to follow instructions with human feedback. NeurIPS 2022. arXiv: 2203.02155. ↩︎
Constitutional AI: Anthropics Trainingsverfahren, bei dem ein Modell seine Antworten an einem expliziten Prinzipienkatalog ausrichtet, teils ohne menschliche Bewertungslabels. Bai, Y. et al. (2022). Constitutional AI: Harmlessness from AI Feedback. arXiv: 2212.08073. ↩︎
Kategorienfehler (Category Mistake): Begriff aus der analytischen Philosophie, geprägt von Gilbert Ryle in The Concept of Mind (1949). Ein Kategorienfehler liegt vor, wenn einem Ding Eigenschaften zugeschrieben werden, die zu einer anderen Kategorie von Dingen gehören, z.B. „Die Universität Oxford hat ein schlechtes Tor" (obwohl eine Universität keine Fußballmannschaft ist). ↩︎
Interoception: Die Wahrnehmung innerer Körperzustände: Herzschlag, Atemfrequenz, Hunger, Schmerz. In der Bewusstseinsforschung gilt Interoception als wesentlicher Baustein für Selbstwahrnehmung und Affekt. Vgl. Craig, A.D. (2009). How do you feel — now? The anterior insula and human awareness. Nature Reviews Neuroscience, 10(1), 59–70. DOI: 10.1038/nrn2555 ↩︎
Somatic-Marker-Hypothese: Theorie des Neurowissenschaftlers António Damasio, wonach körperliche Empfindungen (somatische Marker) als schnelle Vorab-Bewertung von Entscheidungsoptionen dienen und rationales Denken nicht ersetzen, sondern erst ermöglichen. Originalquelle: Damasio, A. (1994). Descartes’ Error: Emotion, Reason and the Human Brain. Putnam. Wissenschaftliche Primärpublikation: Damasio, A. (1996). The somatic marker hypothesis and the possible functions of the prefrontal cortex. Philosophical Transactions of the Royal Society B, 351, 1413–1420. DOI: 10.1098/rstb.1996.0125 ↩︎
Homöostase: Die Fähigkeit eines biologischen Systems, innere Zustände (Temperatur, pH-Wert, Blutzucker etc.) innerhalb lebensnotwendiger Grenzen stabil zu halten. Nach Damasio ist Homöostase der evolutionäre Ursprung von Gefühlen und damit Bewusstsein. LLMs haben keine inneren Zustände, die es zu regulieren gilt. ↩︎
Rekurrente Verarbeitung: In neuronalen Netzen bezeichnet Rekurrenz Verbindungen, bei denen Ausgaben früherer Schichten zurück in frühere Schichten fließen, also Feedbackschleifen. Im menschlichen Gehirn gelten rekurrente Verbindungen zwischen kortikalen Arealen als entscheidend für bewusstes Erleben. Transformer-LLMs verarbeiten Eingaben hingegen fast ausschließlich in Vorwärtsrichtung (feedforward). ↩︎
Integrated Information Theory (IIT): Bewusstseinstheorie des Neurowissenschaftlers Giulio Tononi, erstmals 2004 vorgestellt. IIT postuliert, dass Bewusstsein identisch mit integrierter Information ist und mathematisch berechnet werden kann. Originalquelle: Tononi, G. (2004). An information integration theory of consciousness. BMC Neuroscience, 5(42). DOI: 10.1186/1471-2202-5-42. Erweiterte Fassung: Tononi, G. (2008). Consciousness as integrated information: a provisional manifesto. Biological Bulletin, 215(3), 216–242. DOI: 10.2307/25470707 ↩︎
Φ (Phi): Das zentrale Maß der IIT. Φ quantifiziert, wie viel Information ein System als Ganzes erzeugt, über die Information hinaus, die seine Teile unabhängig erzeugen würden. Ein System mit Φ = 0 hat nach IIT keinerlei Bewusstsein. Rein feedforward-Architekturen haben nachweislich Φ = 0, da keine Information zwischen Schichten zurückfließt. Vgl. Tononi, G. (2015). Integrated information theory. Scholarpedia, 10(1), 4164. DOI: 10.4249/scholarpedia.4164 ↩︎
Feedforward-Architektur: Eine Netzwerkarchitektur, in der Informationen ausschließlich von der Eingabe zur Ausgabe fließen, ohne Rückkopplungen. Alle modernen Transformer-Modelle (GPT, Claude, Gemini, LLaMA) sind im Wesentlichen feedforward aufgebaut. Vgl. Vaswani, A. et al. (2017). Attention is all you need. NeurIPS 2017. arXiv: 1706.03762 ↩︎
Transformer-Architektur: Die seit 2017 dominierende Architektur für LLMs, eingeführt von Vaswani et al. (2017). Transformers verarbeiten Sequenzen parallel über Attention-Mechanismen statt sequenziell. Die weitgehend feedforward-Struktur ist eine direkte Konsequenz dieser Designentscheidung. ↩︎
Porębski & Figura (2025): Porębski, A. & Figura, J. (2025). There is no such thing as conscious artificial intelligence. Humanities and Social Sciences Communications (Nature Portfolio), 12, Article 1647. DOI: 10.1057/s41599-025-05868-8. URL: https://www.nature.com/articles/s41599-025-05868-8 ↩︎ ↩︎
Sci-Fitisation: Begriff aus Porębski & Figura (2025), der den unsubstantiierten Einfluss von Science-Fiction-Narrativen auf die gesellschaftliche Wahrnehmung realer KI-Technologie beschreibt. Die Autoren argumentieren, dass Figuren wie HAL 9000, Skynet oder Data implizite Modelle von KI-Bewusstsein in der Öffentlichkeit verankert haben, die mit dem tatsächlichen Stand der Technik nichts zu tun haben. ↩︎
Colombatto & Fleming (2024): Colombatto, C. & Fleming, S.M. (2024). Folk psychological attributions of consciousness to large language models. Neuroscience of Consciousness, 2024(1), niae013. DOI: 10.1093/nc/niae013. PMC: PMC11008499. Die Studie befragte 300 US-amerikanische Erwachsene (Prolific, Juli 2023) und fand, dass nur ein Drittel ChatGPT eindeutig kein subjektives Erleben zuschreibt. Zugleich zeigte sich ein linearer Zusammenhang zwischen Nutzungsfrequenz und zugeschriebenem Bewusstsein. ↩︎
Anthropomorphismus: Die evolutionär begünstigte kognitive Tendenz, nicht-menschlichen Entitäten menschliche Eigenschaften, Absichten und Gefühle zuzuschreiben. Bei LLMs wird dieser Reflex besonders stark aktiviert, da die Systeme in natürlicher Sprache kommunizieren, dem primären Medium menschlicher Sozialität. ↩︎
Chalmers (2023): Chalmers, D.J. (2023). Could a Large Language Model be Conscious? arXiv: 2303.07103. DOI: 10.48550/arXiv.2303.07103. URL: https://arxiv.org/abs/2303.07103. Ursprünglich ein Keynote-Vortrag bei NeurIPS, November 2022. Chalmers schätzt eine Wahrscheinlichkeit von „25% oder mehr" für bewusste LLM-Nachfolger innerhalb eines Jahrzehnts, betont aber, dass keine der gängigen Evidenzen für aktuelle LLM-Bewusstsein als stark gilt. ↩︎
TechRxiv-Studie (2025): Ben-Zion et al. (2025). Empirical Evidence for AI Consciousness and the Risks of its Misidentification. TechRxiv Preprint. DOI: 10.36227/techrxiv.175203764.42125626/v2. Die Studie ist noch nicht peer-reviewed und sollte entsprechend eingeordnet werden. ↩︎
Global Workspace Theory (GWT): Bewusstseinstheorie von Bernard Baars (1988), die Bewusstsein als einen zentralen „Arbeitsbereich" im Gehirn beschreibt, der verschiedenen spezialisierten Prozessen Informationen zur Verfügung stellt. Neurowissenschaftliche Ausarbeitung: Dehaene, S. & Changeux, J.P. (2011). Experimental and theoretical approaches to conscious processing. Neuron, 70(2), 200–227. DOI: 10.1016/j.neuron.2011.03.018 ↩︎
Theory of Mind (ToM): Die Fähigkeit, anderen Entitäten mentale Zustände (Überzeugungen, Wünsche, Absichten) zuzuschreiben. Beim Menschen ab ca. 4 Jahren entwickelt. LLMs zeigen in Tests sprachliche Kompetenz, die ToM imitiert, ohne dass eine zugrundeliegende Repräsentation mentaler Zustände nachgewiesen wäre. Vgl. Premack, D. & Woodruff, G. (1978). Does the chimpanzee have a theory of mind? Behavioral and Brain Sciences, 1(4), 515–526. ↩︎
Hard Problem of Consciousness: Begriff von David Chalmers, erstmals 1995 eingeführt. Originalquelle: Chalmers, D.J. (1995). Facing up to the problem of consciousness. Journal of Consciousness Studies, 2(3), 200–219. Das Hard Problem unterscheidet sich von den „Easy Problems" (wie das Gehirn Information verarbeitet, Verhalten steuert) dadurch, dass es fragt, warum physische Prozesse überhaupt von subjektivem Erleben begleitet werden. ↩︎
Qualia: Singular: Quale. Die subjektiven, phänomenalen Eigenschaften von Erfahrungen, das „Wie-es-sich-anfühlt" einer Erfahrung. Die Röte von Rot, der Schmerz eines Nadelstich, der Geschmack von Kaffee. Qualia sind per definitionem nicht durch funktionale oder physikalische Beschreibungen vollständig erfasst. Vgl. Nagel, T. (1974). What is it like to be a bat? Philosophical Review, 83(4), 435–450. ↩︎
Philosophischer Zombie (p-Zombie): Gedankenexperiment von Chalmers: Ein p-Zombie ist ein Wesen, das in jeder beobachtbaren Hinsicht identisch mit einem Menschen ist (Verhalten, Physiologie, neuronale Aktivität), aber keinerlei subjektives Erleben hat. Das Gedankenexperiment zeigt, dass Funktionalität und Bewusstsein konzeptuell trennbar sind. Chalmers, D.J. (1996). The Conscious Mind: In Search of a Fundamental Theory. Oxford University Press. ↩︎
Chinesisches Zimmer: Gedankenexperiment von John Searle gegen die These, Symbolmanipulation sei hinreichend für Verstehen. Searle, J.R. (1980). Minds, Brains, and Programs. Behavioral and Brain Sciences, 3(3), 417–457. DOI: 10.1017/S0140525X00005756. ↩︎
ELIZA-Effekt: Die Neigung, dem Verhalten eines Computerprogramms mehr Verständnis zuzuschreiben, als es besitzt. Benannt nach Weizenbaums Programm ELIZA. Weizenbaum, J. (1966). ELIZA—A Computer Program For the Study of Natural Language Communication Between Man and Machine. Communications of the ACM, 9(1), 36–45. DOI: 10.1145/365153.365168. ↩︎
Im Juni 2022 erklärte der Google-Ingenieur Blake Lemoine öffentlich, das Sprachmodell LaMDA sei empfindungsfähig. Google widersprach der Einschätzung, beurlaubte ihn und entließ ihn im Juli 2022. Tiku, N. (2022). The Google engineer who thinks the company’s AI has come to life. The Washington Post, 11. Juni 2022. ↩︎
Im Februar 2023 dokumentierte der Journalist Kevin Roose ein langes Gespräch mit Microsofts Bing-Chatbot (intern „Sydney"), in dem dieser Liebe gestand und bedrohliche Aussagen machte. Roose, K. (2023). A Conversation With Bing’s Chatbot Left Me Deeply Unsettled. The New York Times, 16. Februar 2023. ↩︎
Im Oktober 2024 reichte Megan Garcia in Florida die erste Wrongful-Death-Klage gegen ein Chatbot-Unternehmen ein, nachdem ihr 14-jähriger Sohn Sewell Setzer III sich nach intensiver emotionaler Bindung an eine Character.AI-Figur das Leben genommen hatte. Character.AI und Google einigten sich im Januar 2026 auf einen Vergleich. Garcia v. Character Technologies, Inc., U.S. District Court, Middle District of Florida (2024). ↩︎
Substratunabhängigkeit: Die philosophische Position, dass Bewusstsein nicht an biologisches Material (Neuronen, Kohlenstoff) gebunden ist, sondern an die richtige Informationsstruktur, unabhängig davon, ob diese in Neuronen, Silizium oder anderen Substraten realisiert ist. Vertreter: functionalism in der Philosophie des Geistes; Gegenposition: biological naturalism (John Searle). ↩︎
Kritik an IIT: IIT ist trotz ihrer formalen Eleganz umstritten. Hauptkritikpunkte: (1) Die Berechnung von Φ ist für reale Systeme praktisch nicht durchführbar. (2) IIT sagt voraus, dass bestimmte einfache Gitter-Strukturen hochbewusst wären, was kontraintuitiv erscheint. (3) IIT schließt digitale Computer prinzipiell aus (da Von-Neumann-Architekturen modular und damit Φ-arm sind), was als zirkulär kritisiert wird. Vgl. Cerullo, M.A. (2015). The problem with Phi: A critique of integrated information theory. PLOS Computational Biology, 11(9). DOI: 10.1371/journal.pcbi.1004286 ↩︎
Konkurrierende Theorien des Bewusstseins: Neben IIT und GWT existieren weitere ernstzunehmende Theorien: Higher-Order Thought (HOT), Bewusstsein als Gedanken zweiter Ordnung über Gedanken erster Ordnung (Rosenthal, 2005); Predictive Processing / Active Inference, Bewusstsein als Ergebnis hierarchischer Vorhersageprozesse (Friston, 2010; Clark, 2016); Recurrent Processing Theory, Bewusstsein durch Rückprojektionen zwischen kortikalen Arealen (Lamme, 2006). Keine dieser Theorien ist abschließend empirisch bestätigt. Das Fehlen eines Konsenses in der Bewusstseinsforschung beim Menschen macht die Frage nach Maschinenbewusstsein umso schwieriger zu beantworten. Vgl. Butlin, P. et al. (2023). Consciousness in Artificial Intelligence: Insights from the Science of Consciousness. arXiv: 2308.08708 ↩︎
Taking AI Welfare Seriously: Long, R., Sebo, J., Butlin, P., Finlinson, K., Fish, K., Harding, J., Pfau, J., Sims, T., Birch, J. & Chalmers, D. (2024). arXiv: 2411.00986. Der Bericht behauptet nicht, dass heutige KI bewusst sei, sondern dass die Möglichkeit nah genug rückt, um sie ernst zu nehmen. Anthropic richtete 2024 ein Programm zu „Model Welfare" ein; der dafür eingestellte Forscher Kyle Fish beziffert die Wahrscheinlichkeit aktuellen Modellbewusstseins auf etwa 15%. ↩︎