Nodes, Expressions und der erste Workflow ohne KI

Artikel 4 · Serie: Einstieg in n8n
Das ist der erste Artikel der Reihe, in dem ein Workflow tatsächlich läuft. Wir empfangen einen HTTP-POST, der Body wird erarbeitet, ein Ticket klassifiziert und eine JSON-Antwort zurückschickt. Der Workflow nutzt drei Kern-Knotentypen: Set, Code und Switch. Zu verstehen, was jeder davon kann — und was nicht — ist das primäre Lernziel dieses Artikels.
Das sekundäre Ziel: am Ende läuft ein regelbasierter Classifier auf dem gepinnten Datensatz aus Artikel 3, und seine strukturellen Grenzen sind explizit dokumentiert — nicht als Designfehler, sondern als bewusstes Argument für den Wechsel zur KI-Klassifikation in Artikel 6.
Der Code zu diesem Artikel liegt auf Codeberg, Tag v0.4: codeberg.org/rotecodefraktion/n8n-einstieg.
Das Item-Modell in Bewegung
Artikel 1 hat das Item-Modell theoretisch eingeführt: n8n übergibt Daten zwischen Knoten als Arrays von Items. Jedes Item ist ein JSON-Objekt. Ein Workflow verarbeitet jedes Item einzeln oder als Batch, je nach Konfiguration.
In der Praxis macht diese Unterscheidung an zwei Stellen konkret einen Unterschied.
In Expressions — allem zwischen {{ }} — steht $json für das JSON-Objekt des aktuellen Items. Das funktioniert erwartungsgemäß:
{{ $json.body.subject }}
ergibt den Wert unter body.subject im aktuellen Item.
Im Code-Node ist $json nicht verfügbar. Die Laufzeitumgebung im Code-Node ist JavaScript mit einem eigenen Scope — nicht der Expression-Evaluator. Die äquivalente Zugriffsform ist:
const itemData = $input.item.json;
Der Monaco-Editor in n8n 2.21.4 unterstreicht $json im Code-Node rot.
Regel für diesen Workflow: In Expressions $json.field, im Code-Node-Body $input.item.json.field.
Expressions — Syntax und Fallstricke
Expressions in n8n folgen Template-Literal-Syntax: {{ ausdruck }}. Die Expression-Engine wertet JavaScript-ähnlichen Code innerhalb der doppelten geschweiften Klammern aus.
Drei Fehlerquellen treten im Alltag regelmäßig auf.
Undefined-Felder. Wenn $json.body.language nicht existiert, wertet der Ausdruck zu undefined aus, nicht zu einem leeren String. Ein nachgelagerte Knoten, der einen String erwartet, bekommt undefined und verhält sich möglicherweise unerwartet. Defensiv: {{ $json.body.language ?? 'de' }}.
Typ-Mismatches. $json.body.sla_hours kann als String "8" ankommen statt als Zahl 8, wenn der Set-Node ein Feld als Fixed String gesetzt hat. Mathematische Operationen scheitern dann oder produzieren NaN. Der Set-Node hat im Fixed-Modus separate Typen für Strings und Zahlen — der falsche Typ ist schnell gewählt.
Fixed vs. Expression im Set-Node. Der Set-Node hat pro Feld einen Toggle zwischen Fixed (Literalwert) und Expression (ausgewertetes {{ }}). In n8n 2.21.4 erscheint dieser Toggle nur bei Hover und persistiert visuell nicht. Die zuverlässige Methode, ein Feld als Expression zu setzen: das Feld aus dem INPUT-Panel links direkt in das Zielfeld ziehen. Das funktioniert aber nur nach einem erfolgreich ausgeführten Vorgängerknoten.
Ablauf für den Normalize-Knoten in diesem Workflow:
- Webhook-Knoten anlegen, „Listen for Test Event" klicken
- Test-POST per curl schicken
- Normalize-Knoten öffnen — das INPUT-Panel zeigt jetzt die echte Webhook-Payload
- Felder aus dem INPUT-Panel per Drag-and-Drop in die Set-Node-Felder ziehen
Ohne vorherigen Test-Run ist das INPUT-Panel leer, Drag-and-Drop funktioniert nicht.
Set-Node oder Code-Node?
Beide Knoten transformieren Daten. Das Entscheidungskriterium ist einfach:
| Situation | Wahl |
|---|---|
| Felder umbenennen, zusammenführen, herausfiltern | Set-Node |
Einzelnen Wert berechnen, z. B. .toLowerCase() | Set-Node mit Expression |
Bedingte Logik, Schleifen, reduce, map | Code-Node |
| Keyword-Matching über mehrere Kategorien | Code-Node |
| Externe Bibliothek aufrufen | Code-Node |
Der Set-Node ist deklarativ: man definiert, wie der Output aussehen soll, nicht wie man ihn berechnet. Das ist direkt im Canvas lesbar, ohne den Knoten zu öffnen. Der Code-Node ist imperativ: man schreibt JavaScript, und im Canvas steht nur der Knotenname.
Für den Normalize-Schritt — Felder aus dem Webhook-Body extrahieren und text_normalized aufbauen — ist der Set-Node die richtige Wahl. Fünf Feldzuweisungen, eine davon eine einfache String-Konkatenation mit .toLowerCase(). Keine Conditions, keine Schleifen.
Für den Classify-Keywords-Schritt — text_normalized gegen 30+ Keywords über sechs Kategorien matchen, jede Kategorie bewerten, den Top-Match wählen — ist der Code-Node die richtige Wahl. Das ist eine Reduce-Operation über eine Liste. Der Set-Node kann das nicht ausdrücken.
Routing mit dem Switch-Node
Der Switch-Node leitet jedes Item an einen von mehreren Outputs weiter, basierend auf Bedingungen. Modus Rules: jede Regel ist ein if-Zweig. Der Knoten wertet die Regeln der Reihe nach aus und schickt das Item an den ersten matchenden Zweig.
Konfiguration für diesen Workflow:
- Regel 1:
{{ $json.category }}gleichsap-basis→ Output:sap-basis - Regel 2:
{{ $json.category }}gleichsap-functional→ Output:sap-functional - Regel 3:
{{ $json.category }}gleichinfrastruktur→ Output:infrastruktur - Regel 4:
{{ $json.category }}gleichcloud→ Output:cloud - Regel 5:
{{ $json.category }}gleichsecurity-pki→ Output:security-pki
Das linke Feld jeder Regel muss im Expression-Modus stehen. Der gleiche Hover-Toggle wie beim Set-Node gilt hier — sicherstellen, dass das Feld {{ ... }}-Syntax zeigt und nicht den Literal-String $json.category.
Fallback-Zweig. Ein Switch-Node ohne Default-Zweig lässt Items, die keiner Regel entsprechen, stumm fallen. Die Option heißt in n8n 2.21.4 „Extra Output" (die Dokumentation nennt sie „Fallback Output" — gleiche Funktion, anderes Label). Mit aktivem Extra Output erscheint ein sechster Output, der alles auffängt, was die fünf Regeln nicht matchen — in diesem Workflow Tickets mit category: sonstiges.
Die Option „Extra Output" befindet sich unten im Settings-Panel des Knotens. Aktivieren. Einen sechsten Output verbinden mit dem Label: Sonstiges-Set-Node.
UI-Hinweis: die Option „Convert types where required" in n8n 2.21.4 entspricht „Less Strict Type Validation" in der Dokumentation. Gleiche Semantik, anderes Label.
Der Workflow Schritt für Schritt
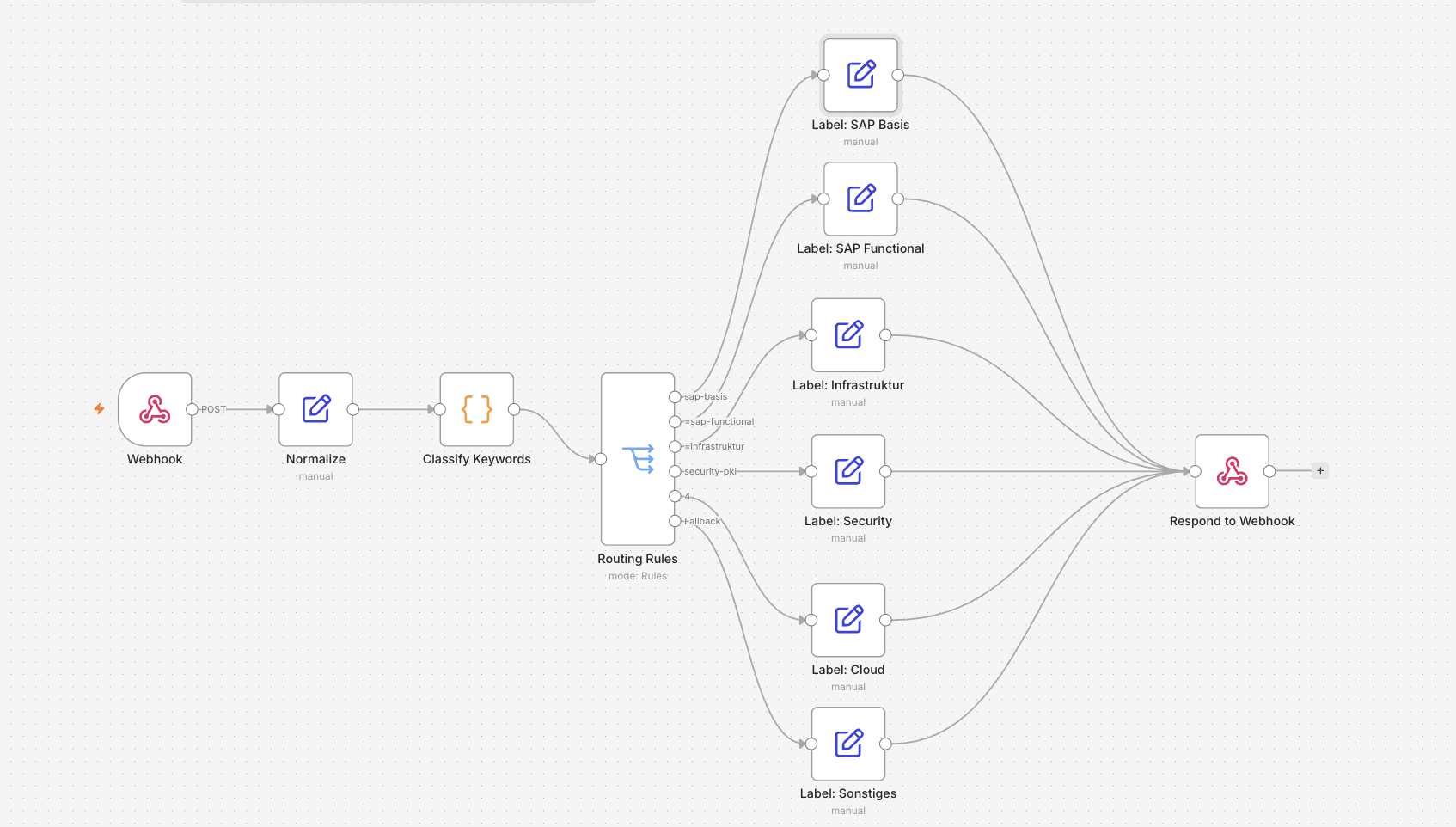
Der Workflow hat 11 Knoten. Bauen in dieser Reihenfolge.
Knoten 1 — Webhook
Knotentyp: „Webhook"
- HTTP Method:
POST - Path:
ticket-classify - Respond:
Using Respond to Webhook Node - Authentication:
None
Production-URL nach dem Publish: https://<host>/webhook/ticket-classify. Test-URL: https://<host>/webhook-test/ticket-classify. Die Test-URL ist nur aktiv, solange der Workflow im „Listen for Test Event"-Modus ist.
Knoten 2 — Normalize
Knotentyp: „Edit Fields (Set)"
- Mode:
Manual Mapping - „Include in Output: All Input Fields" → aus
Fünf Felder, alle im Expression-Modus:
| Feld | Expression |
|---|---|
id | {{ $json.body.id }} |
subject_raw | {{ $json.body.subject }} |
body_raw | {{ $json.body.body }} |
language | {{ $json.body.language }} |
text_normalized | {{ ($json.body.subject + ' ' + $json.body.body).toLowerCase() }} |
Den Knoten über Doppelklick auf den Panel-Titel in Normalize umbenennen.
Knoten 3 — Classify Keywords
Knotentyp: „Code"
- Mode:
Run Once for Each Item - Language:
JavaScript
const itemData = $input.item.json;
const text = itemData.text_normalized || '';
const CATEGORIES = [
{
id: 'sap-basis',
keywords: [
'sm50', 'stms', 'abap-dump', 'transport', 'rfc-verbindung',
'rfc connection', 'kernel', 'basis', 'sap-gui', 'workprozess',
'work process', 'sap login', 'sap-login',
],
},
{
id: 'sap-functional',
keywords: [
'buchungsbeleg', 'me21n', 'bestellung', 'lieferung', 'abrechnung',
'purchase order', 'vendor', 'material', 'sd', 'fi', 'mm', 'hr',
'delivery', 'invoice',
],
},
{
id: 'infrastruktur',
keywords: [
'server', 'raid', 'nfs', 'backup', 'latenz', 'netzwerk', 'storage',
'sicherung', 'disk', 'network', 'bandwidth', 'outage',
],
},
{
id: 'cloud',
keywords: [
'azure', 'kubernetes', 'pod', 'terraform', 'aks', 'subscription',
'pipeline', 'container', 'devops', 'cloud', 'deployment',
],
},
{
id: 'security-pki',
keywords: [
'zertifikat', 'certificate', 'cve', 'su53', 'berechtigung',
'penetration', 'pki', 'ssl', 'tls', 'auth', 'permission',
'vulnerability',
],
},
];
const scored = CATEGORIES.map(c => ({
id: c.id,
matches: c.keywords.filter(kw => text.includes(kw)).length,
}));
const best = scored.reduce((a, b) => (b.matches > a.matches ? b : a));
const scores = {};
scored.forEach(s => { scores[s.id] = s.matches; });
return {
json: {
...itemData,
category: best.matches > 0 ? best.id : 'sonstiges',
match_count: best.matches,
scores,
},
};
$input.item.json, nicht $json. Den Knoten in Classify Keywords umbenennen.
Knoten 4 — Routing Rules
Knotentyp: „Switch", Modus: Rules
Fünf Regeln, je:
- Value 1:
{{ $json.category }}(Expression-Modus) - Operation: „is equal to"
- Value 2: Kategorie-ID (Fixed-Modus)
„Extra Output" am Ende des Settings-Panels aktivieren. Jeden Output über „Rename Output" beschriften: sap-basis, sap-functional, infrastruktur, cloud, security-pki. Der Fallback ist der sechste Output. Knoten in Routing Rules umbenennen.
Knoten 5a–5f — Label-Nodes
Sechs Set-Nodes, einer pro Output des Switch:
| Knoten | label | sla_hours | response_text |
|---|---|---|---|
| Label: SAP Basis | SAP Basis | 8 | Ticket der Kategorie SAP Basis. Bearbeitung durch Basis-Team innerhalb von 8 Stunden. |
| Label: SAP Functional | SAP Functional | 16 | Ticket der Kategorie SAP Functional. Bearbeitung durch Functional-Team innerhalb von 16 Stunden. |
| Label: Infrastruktur | Infrastruktur | 12 | Ticket der Kategorie Infrastruktur. Bearbeitung durch Infra-Team innerhalb von 12 Stunden. |
| Label: Cloud | Cloud | 12 | Ticket der Kategorie Cloud. Bearbeitung durch Cloud-Team innerhalb von 12 Stunden. |
| Label: Security | Security / PKI | 4 | Ticket der Kategorie Security/PKI. Eskalation innerhalb von 4 Stunden. |
| Label: Sonstiges | Sonstiges | 24 | Ticket ohne Kategorie. Manuelle Sichtung innerhalb von 24 Stunden. |
Jeder Set-Node: „Include in Output: All Input Fields" → an. Drei zusätzliche Felder als Fixed String: label, sla_hours (als Zahl), response_text.
Knoten 6 — Respond to Webhook
Knotentyp: „Respond to Webhook"
- Response Mode:
First Incoming Item - Response Code:
200
Alle sechs Label-Nodes verbinden mit diesem einen Knoten. n8n erlaubt mehrere eingehende Verbindungen, weil der Switch-Node sicherstellt, dass pro Item nur ein Zweig feuert.
Publish. Nach dem Verbinden aller Knoten: Cmd+S zum Speichern, dann „Publish". Die Production-URL ist erst nach dem Publish aktiv — Cmd+S allein reicht nicht.
Smoke-Test gegen die Production-URL:
curl -k -X POST https://localhost/webhook/ticket-classify \
-H 'Content-Type: application/json' \
-d '{
"id": "TKT-9999",
"subject": "SAP-Login nach Passwortreset",
"body": "SM50 meldet Verbindungsausfall, RFC-Verbindung tot",
"language": "de"
}'
Erwartete Antwort (gekürzt):
{
"id": "TKT-9999",
"category": "sap-basis",
"match_count": 2,
"label": "SAP Basis",
"sla_hours": 8
}
Tickets einspeisen
Das Script scripts/seed-tickets.py lädt Tickets aus testdata/tickets.parquet und schickt jeden Eintrag per POST an den Webhook. Ergebnis: Accuracy und Statistik pro Kategorie.
cd n8n-einstieg
uv run scripts/seed-tickets.py \
--webhook-url https://localhost/webhook/ticket-classify \
--limit 30 \
--insecure
--insecure überspringt die TLS-Prüfung für das selbst-signierte Caddy-Zertifikat. --limit 30 nimmt die ersten 30 Tickets aus dem gepinnten Datensatz.
Das Script nutzt PEP 723 Inline-Abhängigkeiten: httpx und pyarrow sind im Script-Header deklariert und werden von uv run beim ersten Aufruf automatisch installiert. Kein separates requirements.txt nötig.
Auf 30 Tickets aus dem gepinnten Datensatz: 29 von 30 korrekt klassifiziert (97%). Latenz p50 rund 10 ms, Maximum unter 120 ms — weit unter dem Limit von 500 ms aus der Spec.
Replay-Test
Die pytest-Suite in tests/ läuft dieselben 20 Tickets durch den laufenden Workflow und prüft Kategorie-Korrektheit und Antwortzeit.
cd n8n-einstieg/tests
uv run --with pytest --with httpx --with pyarrow pytest
Die Webhook-URL kommt aus der Umgebungsvariable N8N_WEBHOOK_URL (Default: https://localhost/webhook/ticket-classify).
40 Test-Cases insgesamt:
- 20×
test_classifier_category_matches_ground_truth— Kategorie gegen Ground-Truth austickets.parquet - 20×
test_classifier_latency_under_500ms— Antwortzeit unter 500 ms
TKT-0005 ist mit pytest.mark.xfail(strict=True) markiert. Der Test wird erwartet zu scheitern. Wenn er nicht scheitert, meldet pytest einen Fehler — weil dann ein bekannter Miss plötzlich korrekt wäre, was eine Regression in umgekehrter Richtung bedeutet. Bei korrekt laufendem Classifier: 39 passed, 1 xfailed.
Die Grenzen des Keyword-Matchings
TKT-0005 ist der dokumentierte Lehrfall.
Ticket (Englisch, Kategorie sap-basis, Persona admin-precise):
- Subject: „SAP GUI connection timeout after VPN change"
- Body: „Since the VPN gateway migration, SAP GUI shows timeout after 2 minutes idle. RFC destination PRD_RFC is affected."
Klassifikations-Ergebnis: sonstiges, match_count: 0.
Der Classifier findet kein einziges Keyword. Warum:
| Im Ticket | Keyword in der Liste | Treffer? |
|---|---|---|
SAP GUI (mit Leerzeichen) | sap-gui (mit Bindestrich) | ✗ |
RFC destination | rfc connection / rfc-verbindung | ✗ |
VPN gateway | vpn-verbindung / vpn connection | ✗ |
Die Keyword-Liste ist deutsch-zentriert mit Bindestrich-Tokens. Das Ticket schreibt dieselben Konzepte mit Leerzeichen und leicht abweichender Vokabel. Substring-Match ohne semantisches Verständnis scheitert.
Das ist kein Fehler im Classifier-Design — es ist die Eigenschaft, die regelbasierte Klassifikation von KI-Klassifikation trennt. Ein Sprachmodell erkennt, dass „SAP GUI", „SAP-GUI" und „SAPgui" denselben Begriff meinen. Der Keyword-Classifier kann das ohne expliziten Eintrag nicht.
Drei weitere Muster, die ihn in der Praxis treffen:
Abkürzungen. „Berechtigungsproblem" matched su53. „User kann T-Code nicht aufrufen" matched gar nicht — obwohl der Sachverhalt identisch ist. Die Verbindung zwischen Beschreibung und Code existiert nur, wenn sie explizit in der Keyword-Liste steht.
Vokabular-Drift. Englische Tickets in SAP-Domänen schreiben work process statt Workprozess, transport request statt Transportauftrag. Jede Abweichung von der Liste ist ein potenzieller Miss. Der Datensatz aus Artikel 3 ist bewusst 60% Deutsch, 40% Englisch — genau damit diese Schwäche sichtbar wird.
Fehlender Eintrag. Dump in SM37 matched nicht sm37, weil sm37 nicht in der Keyword-Liste steht. Wer die Liste pflegt, pflegt im Grunde ein zweites System neben dem Ticket-System. Jede neue SAP-Transaktion, jedes neue Cloud-Produkt, jede neue Abkürzung braucht einen manuellen Eintrag.
Diese Lücken ließen sich durch Erweiterung der Keyword-Listen teilweise schließen. Der Aufwand skaliert aber mit der Domänentiefe: für jede Sprache, jeden Dialekt, jede Abkürzungsvariante wächst die Liste. Das ist die strukturelle Grenze regelbasierter Klassifikation.
Artikel 5 kommt zuerst: der Webhook ist bislang offen — kein API-Key, keine IP-Beschränkung. Authentication gehört vor den Schritt zur KI.
→ Artikel 3: Testdaten, weil echte nicht gehen → Artikel 5: Webhook absichern (erscheint demnächst)