AI-Klassifikation ohne Cloud — der Ticket-Workflow bekommt ein Gehirn

Artikel 6 · Serie: Einstieg in n8n
Der Classifier aus Artikel 4 ordnet Tickets über Keyword-Matching ein. Das funktioniert, solange die richtigen Wörter im Text stehen, und scheitert bei englischen Tickets mit abweichender Schreibweise. Artikel 5 hat diesem Classifier einen authentifizierten Eingang gegeben. In diesem Artikel tauschen wir das Keyword-Matching gegen ein Sprachmodell aus, das semantische Nähe statt exakter Zeichenketten erkennt. Wir bauen das zweimal, mit zwei verschiedenen lokalen Modellen, und am Ende messen wir, ob sich der Aufwand gegenüber der Regel überhaupt lohnt.
Der Code zu diesem Artikel liegt auf Codeberg, Tag v0.6: codeberg.org/rotecodefraktion/n8n-einstieg.
Basic LLM Chain statt AI Agent
n8n bringt mehrere Nodes für Sprachmodelle mit. Der prominenteste ist der AI-Agent-Node, gedacht für Abläufe mit Tools, Memory und mehrstufigem Reasoning. Für eine reine Klassifikation ist er das falsche Werkzeug. Wir brauchen keinen Agenten, der Werkzeuge auswählt, sondern einen einzigen Modellaufruf, dessen Antwort einem festen Schema folgt.
Der erste Versuch mit dem AI-Agent-Node plus angehängtem Structured Output Parser lief gegen eine Wand. Der Parser meldete The AI model returned an empty response, obwohl im Input-Panel sichtbar gültiges JSON lag. Mit aktiviertem Auto-Fix kam stattdessen Model output doesn't fit required format. Ein direkter Test gegen das Modell, außerhalb von n8n, lieferte jedes Mal sauberes Schema-JSON. Das Modell war also nicht das Problem.
Die Erklärung steht in der n8n-Dokumentation selbst:
“Structured output parsing is often not reliable when working with agents. If your workflow uses agents, n8n recommends using a separate LLM-chain to receive the data from the agent and parse it.”
Für die Klassifikation heißt das: Basic LLM Chain statt AI Agent. Die Chain macht genau einen Modellaufruf, der Structured Output Parser hängt direkt daran. Kein Agenten-Loop, der bei kleinen Modellen ins Leere läuft. Der Agent bleibt das richtige Werkzeug, wenn echte Tool-Nutzung oder Gesprächsgedächtnis gebraucht wird, hier nicht.
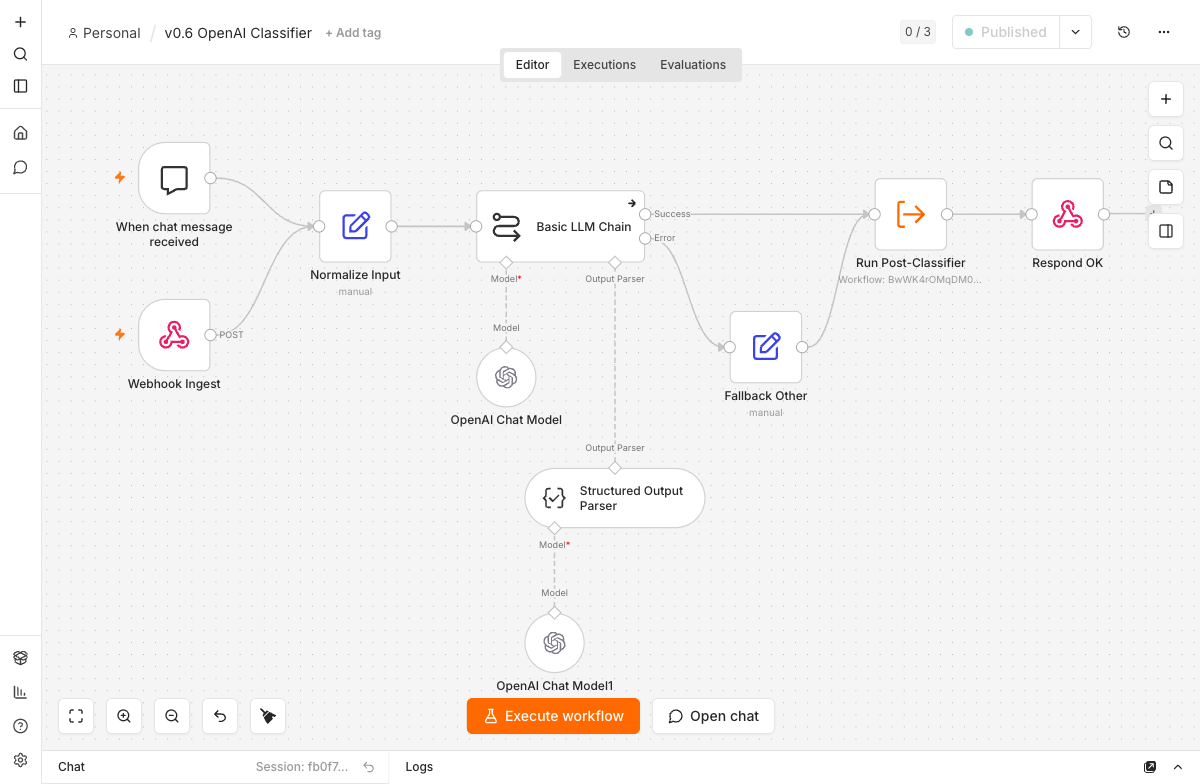
Strukturierter Output mit JSON-Schema
Ein Klassifikator, der freien Text zurückgibt, ist wertlos für die nachgelagerte Verarbeitung. Wir brauchen ein typisiertes Objekt, gegen das ein Switch-Node routen kann. Der Structured Output Parser nimmt ein JSON-Schema entgegen und zwingt die Antwort in diese Form:
{
"type": "object",
"properties": {
"category": {"type": "string", "enum": ["sap-basis", "sap-functional", "infrastruktur", "cloud", "security-pki", "sonstiges"]},
"confidence": {"type": "number", "minimum": 0, "maximum": 1},
"language": {"type": "string", "enum": ["de", "en"]},
"p1_suspected": {"type": "boolean"},
"p1_reason": {"type": "string"}
},
"required": ["category", "confidence", "language", "p1_suspected", "p1_reason"]
}
Die System Message beschreibt die sechs Kategorien mit ihren typischen Begriffen und die Regeln für die einzelnen Felder. confidence ist die Selbsteinschätzung des Modells, p1_suspected markiert vermutete Notfälle, dazu später mehr. Der Auto-Fix-Modus hängt bei einem Schema-Verstoß einen zweiten Modellaufruf an, der die kaputte Antwort reparieren soll. Dieser Reparatur-Pass braucht ein eigenes Chat-Model-Sub-Node, sonst quittiert n8n mit A Model sub-node must be connected and enabled.
Der OpenAI Chat Model-Node bringt einen Schalter mit, der beim ersten Einsatz gegen einen lokalen Server leicht übersehen wird: Use Responses API. Ist er aktiv, ruft der Node nicht /v1/chat/completions, sondern /v1/responses. Der MLX-Server unseres lokalen Stacks kennt diesen Endpoint nicht und antwortet mit einem 404, das langchain in die irreführende Meldung MODEL_NOT_FOUND übersetzt. Wer das sieht, prüft zuerst den Modellnamen — und sucht an der falschen Stelle. Der Fix ist ein Klick: Schalter aus. Ollama dagegen implementiert /v1/responses, dort spielt der Schalter keine Rolle.
Zwei lokale Modelle, kein Cloud-Key
Die Reihe hat Datensouveränität als durchgehendes Thema. Ein Klassifikator, der jedes Ticket an eine Cloud-API schickt, widerspricht dem. Also läuft die Klassifikation lokal, und zwar mit zwei verschiedenen Backends parallel.
Das erste ist Ollama mit qwen2.5:7b, der reproduzierbare Pfad für Leser. Ollama bietet einen OpenAI-kompatiblen Endpoint, der n8n-OpenAI-Chat-Model-Node spricht ihn direkt an. Die Credential bekommt als Base URL http://host.docker.internal:11434/v1 und einen beliebigen API-Key, denn Ollama prüft keinen. host.docker.internal ist nötig, weil n8n im Container läuft und localhost dort auf den Container selbst zeigt, nicht auf den Host.
Das zweite Backend ist unser eigener Hummingbird-MLX-Server mit Qwen3-8B-4bit. Er bietet einen Anthropic-kompatiblen Endpoint unter /v1/messages, also hängen wir dort den Anthropic-Chat-Model-Node an. Die Node-Wahl folgt der Endpoint-Abdeckung: Der OpenAI-Node erreicht Ollama und MLX, der Anthropic-Node erreicht MLX und echtes Claude in der Cloud. Kein einzelner Node deckt alle drei Welten ab.
Ob Ollama oder eigenes Hummingbird-MLX Gateway — die Kernaussage bleibt: Der gesamte Klassifikator läuft ohne API-Key. Ein lokales Modell ersetzt die Cloud vollständig.
Ollama und den Hummingbird-MLX-Server starten
Beide Modell-Backends laufen auf dem Host, nicht im n8n-Container. n8n spricht sie über host.docker.internal an (siehe oben). Es genügt, das Backend zu starten, dessen Chat-Model-Node der Workflow tatsächlich nutzt.
Ollama (OpenAI-kompatibel, Port 11434):
ollama serve &
ollama pull qwen2.5:7b
Prüfen, dass der OpenAI-kompatible Endpoint antwortet:
curl -s http://localhost:11434/v1/models | jq .
Die OpenAI-Credential in n8n bekommt als Base URL http://host.docker.internal:11434/v1 und einen beliebigen API-Key.
Hummingbird-MLX-Gateway (Anthropic-kompatibel, Port 8080):
Das Hummingbird-Gateway aus der gleichnamigen Reihe lässt sich auf zwei Wegen starten. Schnell zum Ausprobieren direkt aus dem Projektverzeichnis:
swift run gateway
Produktionsnäher und mit kürzerer Startzeit über ein Release-Binary (Details in Hummingbird, Artikel 6):
swift build -c release
.build/release/gateway --host 0.0.0.0 --port 8080
Prüfen, dass das Gateway läuft:
curl -s localhost:8080/healthz
curl -s localhost:8080/v1/models | jq .
Die Anthropic-Credential in n8n zeigt auf http://host.docker.internal:8080. Der Anthropic-Chat-Model-Node spricht darüber den Endpoint /v1/messages an.
Beim zweiten Backend nutzen wir nebenbei ein fortgeschrittenes Muster. Der Auto-Fix-Reparatur-Pass muss nicht dasselbe Modell verwenden wie der Hauptaufruf. Im MLX-Workflow ist der Primär-Aufruf das MLX-Qwen3, der Reparatur-Pass aber Ollama-Qwen2.5. Zwei lokale Stacks, die kooperieren. Sinnvoll ist das, wenn das Reparatur-Modell stärker sein soll als das Hauptmodell, oder schlicht ein anderer Anbieter zur Absicherung.
Sprache erkennt kein Sprachmodell
Das Schema enthält ein Feld language. Naheliegend wäre, das Modell die Sprache mitschätzen zu lassen. Eine kurze Messung zeigt, warum das eine schlechte Idee ist. Ein deutsches Ticket über einen AKS-Cluster, voller englischer Fachbegriffe wie Kubernetes, Pod und IAM, stuft Qwen3 als englisch ein. Das kleinere Ollama-Modell zieht umgekehrt englische Tickets ins Deutsche. Beide Modelle driften zu ihrer jeweils stärkeren Trainingssprache.
Sprach-Erkennung ist ein gelöstes Problem, und zwar deterministisch. Die Bibliothek franc-min zählt n-Gramm-Frequenzen und ist immun gegen einzelne Fachbegriffe. Wir lassen das language-Feld also weiter vom Modell füllen, behandeln es aber nur als Diagnosewert und überschreiben es mit dem Ergebnis von franc-min. Ein Code-Node hinter der Chain erledigt das:
const { franc } = require('franc-min');
const txt = $json.pipelineInput || '';
const iso3 = franc(txt, { only: ['deu', 'eng'] });
const detected = iso3 === 'deu' ? 'de' : iso3 === 'eng' ? 'en' : 'unknown';
const c = $json.output;
return [{ json: {
category: c.category,
confidence: c.confidence,
language: detected,
language_llm: c.language,
language_match: c.language === detected,
p1_suspected: c.p1_suspected,
p1_reason: c.p1_reason,
route_pager: (c.p1_suspected === true) || ($json.priority === 'critical'),
} }];
Das Feld language_match macht die Modell-Drift messbar. Über die ganze Evaluation lässt sich so beziffern, wie oft das Modell bei der Sprache daneben lag, ohne dass das Endergebnis darunter leidet.
Externe npm-Pakete im Code-Node sind beim Self-Hosting kein Problem, setzen aber einen kurzen Umweg voraus. Das Paket muss im Docker-Image vorhanden sein, und die Umgebungsvariable NODE_FUNCTION_ALLOW_EXTERNAL muss es freigeben — beides zusammen. Wer npm install direkt im n8n-Installationsverzeichnis probiert, läuft auf einen Fehler: n8n nutzt intern das pnpm-catalog:-Protokoll, das reguläre npm-Aufrufe in seinem Verzeichnis ablehnt. Die saubere Lösung ist ein eigenes Paketverzeichnis, auf das NODE_PATH zeigt:
FROM n8nio/n8n:2.21.4
USER root
RUN mkdir -p /home/node/n8n-libs \
&& cd /home/node/n8n-libs \
&& npm init -y \
&& npm install franc-min \
&& chown -R node:node /home/node/n8n-libs
USER node
ENV NODE_PATH=/home/node/n8n-libs/node_modules
Die zugehörige docker-compose.yml ersetzt image: durch build: . und gibt das Paket frei:
services:
n8n:
build: . # lokales Dockerfile statt Registry-Image
environment:
NODE_FUNCTION_ALLOW_EXTERNAL: "franc-min"
volumes:
- n8n-data:/home/node/.n8n # Credentials und Workflows bleiben erhalten
Beim Neustart nach einer Image-Änderung reicht docker compose up --build allein nicht — der laufende Container wird dabei nicht ausgetauscht. Das Flag --force-recreate erzwingt den Austausch, und mit dem Service-Namen n8n bleibt Postgres unangetastet:
docker compose up --build --force-recreate n8n
Die benannten Volumes n8n-data und postgres-data überleben den Container-Neustart. Credentials, Workflows und Datenbankinhalt bleiben erhalten.
Routing: zwei Signale für den Alarm
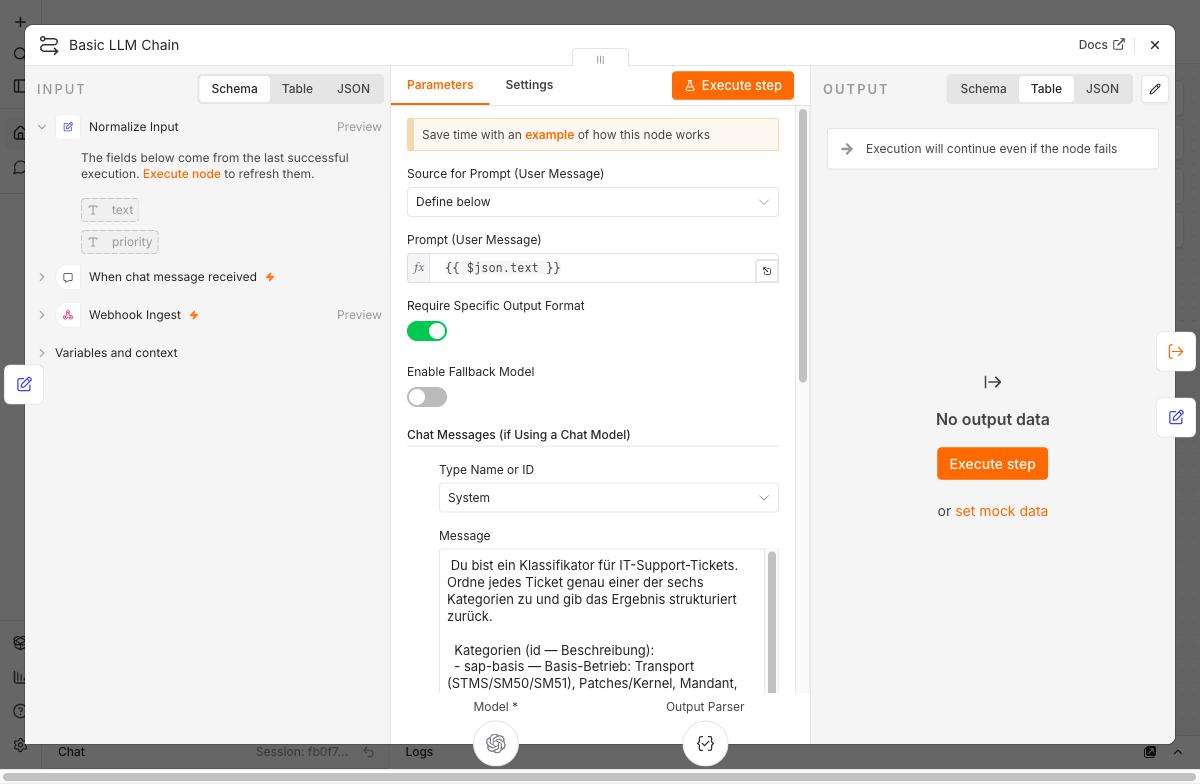
Ein Klassifikator, der nur eine Kategorie zurückgibt, hat seinen Wert noch nicht ausgespielt. Interessant wird es bei der Frage, welche Tickets sofort jemanden wecken müssen. Das Ticketsystem liefert dafür ein Feld priority, gesetzt vom Einreicher. Auf dieses Feld allein ist kein Verlass. Manche Einreicher markieren jede Kleinigkeit als kritisch, andere melden einen Produktivausfall als mittlere Priorität, weil sie das Eskalationsverfahren nicht kennen.
Hier zahlt sich das Sprachmodell aus. Es liest den Fließtext und kann einen stillen Notfall erkennen, den die Einreicher-Priorität verschweigt. Dafür gibt es das Feld p1_suspected. Die System Message beschreibt, wann es gesetzt wird: Produktivausfall, Sicherheitsvorfall, drohender Datenverlust, Geschäftsprozess-Stillstand. Das Feld p1_reason liefert eine kurze Begründung und macht die Entscheidung nachvollziehbar, was für das Vertrauen im Betrieb wichtig ist.
Die Routing-Regel kombiniert beide Signale mit einem Oder. Alarmiert wird, wenn der Einreicher critical gesetzt hat oder das Modell einen P1 vermutet. n8n bietet im Switch-Node pro Regel nur eine einzelne Bedingung, kein Oder über mehrere Bedingungen. Also berechnen wir die Verknüpfung im Code, im Feld route_pager, und der Switch prüft nur dieses eine Boolean. Der Vorteil: Das Routing-Kriterium steht sichtbar im Output und lässt sich beim Debugging direkt ablesen.
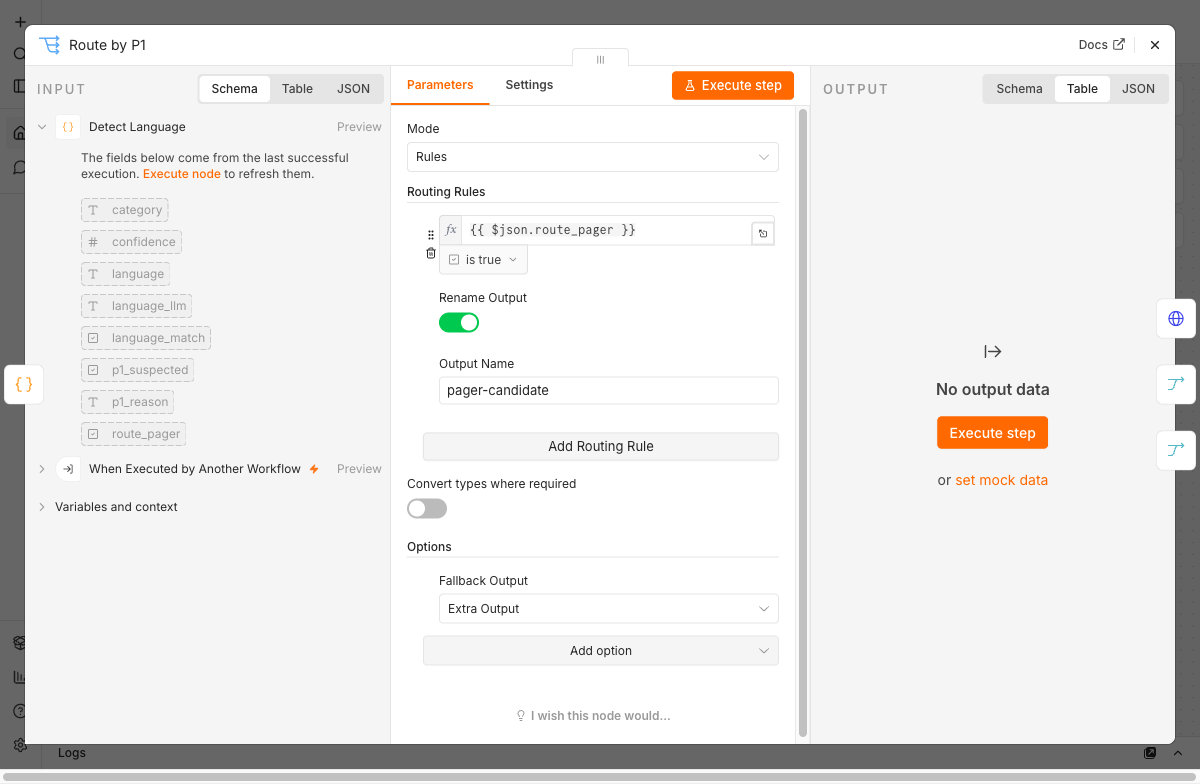
Der Alarm selbst ist ein PagerDuty-Aufruf, in der Demo gegen einen Test-Endpoint. Wichtig ist die Verdrahtung. Der Alarm darf den Datensatz nicht ersetzen, denn ein HTTP-Node liefert seine Antwort zurück und überschreibt damit das durchlaufende Item. Die Lösung ist eine Gabelung. Der Pager-Zweig spaltet sich in zwei Stränge. Einer feuert den Alarm und endet dort, eine Sackgasse. Der andere führt den Klassifikations-Datensatz unberührt weiter zum Merge. Der Fallback-Zweig läuft ohne den Umweg dorthin. Nach dem Merge geht es für alle Tickets gemeinsam weiter zur Queue. So bekommt ein P1-Ticket zusätzlich seinen Alarm, durchläuft aber dieselbe Verarbeitung wie jedes andere.
Eine Pipeline, zwei Eingänge
Zwei Workflows, einer pro Modell, unterscheiden sich nur in einem Punkt: dem Chat-Model-Node. Sprach-Erkennung, Routing, PagerDuty und Queue sind identisch. Dieselbe Logik zweimal zu pflegen, ist eine offene Fehlerquelle.
Also wandert die gemeinsame Nachverarbeitung in einen eigenen Sub-Workflow, die Post-Classifier Pipeline. Beide Backend-Workflows rufen ihn über einen Execute-Workflow-Node auf und übergeben das Klassifikations-Objekt, den Ticket-Text und die Priorität. Dasselbe Muster hat schon Artikel 5 für den regelbasierten Sub-Classifier genutzt. Ein Backend-Wechsel ist damit eine Änderung an genau einem Node, nicht an zwei parallelen Strängen.
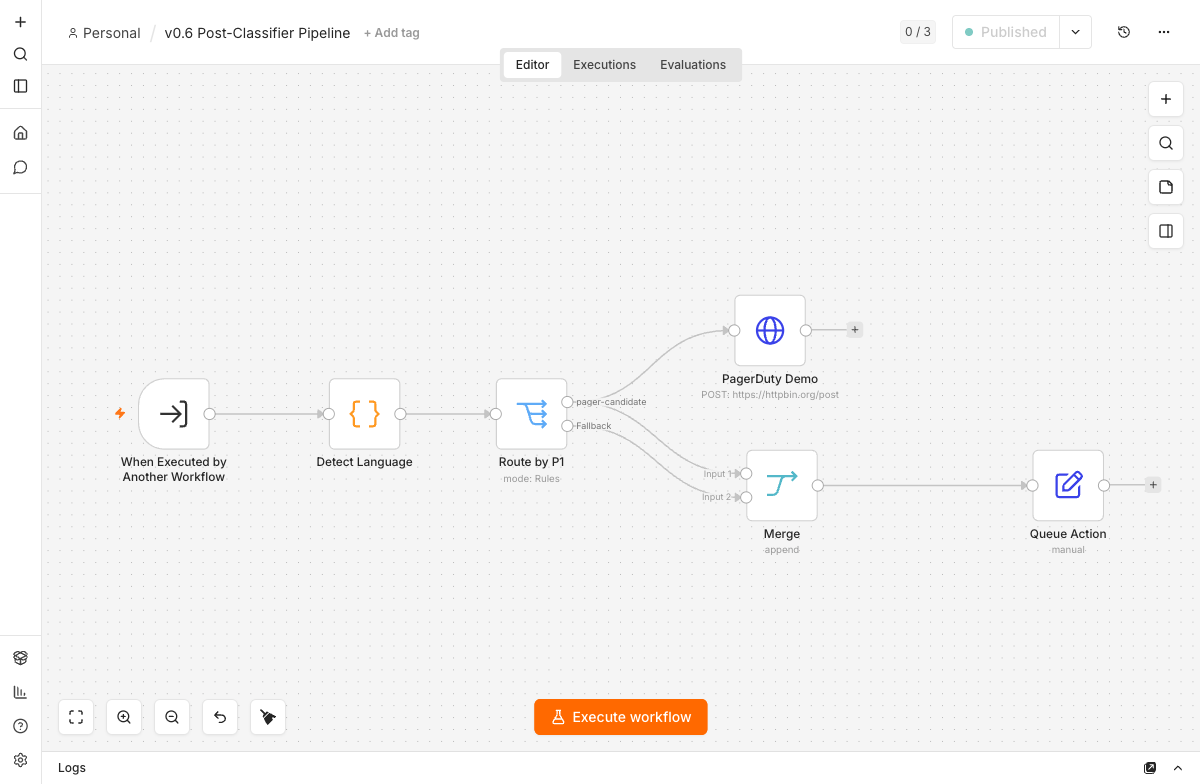
Den Eingang teilen sich Chat-Trigger und Webhook. Der Chat-Trigger ist für die schnelle Iteration während der Entwicklung gedacht, der Webhook ist der produktive Eingang aus Artikel 5, samt Header-Authentifizierung. Ein Set-Node normalisiert beide Quellen auf ein einheitliches Feld, bevor die Chain übernimmt.
Evaluation und Interpretation der Ergebnisse
Hundert Tickets aus dem gepinnten Datensatz, durch beide Workflows, gegen die bekannten Kategorien. Das Skript evaluate.py postet jedes Ticket an den Webhook und baut aus den Antworten eine Confusion Matrix.
| Klassifikator | Kategorie-Genauigkeit | Sprach-Genauigkeit | Zeit (100 Tickets) |
|---|---|---|---|
| Ollama qwen2.5:7b | 97 % | 100 % | 1124 s |
| Hummingbird MLX Qwen3-8B | 98 % | 100 % | 1086 s |
| Regelbasiert (Artikel 4) | 97 % | — | < 1 s |
Die Sprach-Genauigkeit liegt bei beiden Modellen bei 100 Prozent, weil franc-min sie bestimmt und nicht das Modell. Bei der Kategorie liegt der MLX-Stack knapp vorn und ist nebenbei minimal schneller. Beide Modelle übertreffen den im Test verankerten Schwellenwert von 80 Prozent deutlich.
Die regelbasierte Baseline aus Artikel 4 erreicht ebenfalls 97 Prozent. Auf den ersten Blick ein ernüchterndes Ergebnis: Der ganze Aufwand für ein Sprachmodell, und die simple Keyword-Regel hält mit. Auf den zweiten Blick steckt darin die eigentliche Lehre dieses Artikels.
Der Testdatensatz wurde generiert, indem ein Modell angewiesen wurde, pro Kategorie mindestens einen aus einer festen Liste von Begriffen zu verwenden. Genau diese Begriffe sucht der regelbasierte Klassifikator. Die Tickets enthalten also exakt die Wörter, auf die die Regel ausgelegt ist. Der Benchmark gibt der Baseline einen Heimvorteil und unterschätzt den Abstand zum Sprachmodell systematisch. Auf echten Tickets, formuliert von echten Menschen ohne Rücksicht auf Keyword-Listen, würde die Regel deutlich abfallen, das Modell dagegen die semantische Nähe weiter erkennen.
Wer Regel gegen KI vergleicht, darf den Vergleichsdatensatz nicht aus den Keywords der Regel bauen. Sonst misst der Benchmark vor allem den eigenen Testdaten-Aufbau.
Was die Modelle nicht leisten
Die Fehler verteilen sich aufschlussreich. Beim Ollama-Modell liegen alle drei Fehlklassifikationen in der Kategorie cloud, zweimal nach sap-functional, einmal nach infrastruktur. Cloud-Tickets mischen oft Infrastruktur- und Anwendungsvokabular, und das kleinere Modell entscheidet sich dann für den falschen Schwerpunkt. Der MLX-Stack — ohnehin mit einem größeren Modell ausgestattet — streut breiter, mit je einem Fehler an der Grenze zwischen cloud und sonstiges sowie sonstiges und infrastruktur. Der Vorsprung von Hummingbird-MLX gegenüber Ollama ist real, sollte aber mit einem Vorbehalt gelesen werden: Ollama stellt mittlerweile ebenfalls MLX-Modelle für Apple-Silicon-Hardware bereit, und ein Direktvergleich mit denselben Modellgewichten würde ein anderes Bild zeigen.
Das Muster ist verständlich. Schwer fallen den Modellen genau die Tickets, die auch ein Mensch nur mit Kontext sicher einordnet. Ein Confidence-Wert von 1,0 bedeutet nicht, dass das Modell recht hat, sondern nur, dass es sich sicher fühlt. Beide Werte gehören in die Beobachtung, nicht nur die Kategorie.
Auch die Sprach-Episode bleibt eine Mahnung. Ein Sprachmodell ist nicht automatisch das beste Werkzeug für jede sprachnahe Aufgabe. Für die reine Sprach-Erkennung gewinnt der deterministische n-Gramm-Zähler gegen das Milliarden-Parameter-Modell, weil er für genau diese Aufgabe gebaut ist.
Nächster Schritt
Der Workflow klassifiziert jetzt mit einem lokalen Sprachmodell, routet kritische Tickets an einen Alarm und läuft ohne Cloud-Abhängigkeit. Was fehlt, ist Robustheit im Betrieb. Was passiert, wenn der Modellserver nicht antwortet, ein Lauf mitten in der Verarbeitung abbricht oder eine neue Workflow-Version eine alte ablöst. Artikel 7 baut Error Handling, Observability und Versionierung ein.
← Artikel 5: Webhooks, HTTP und Credentials — der produktive Eingang