Ein Eingang, zwei Klassifikatoren — die AI-Pipeline in den Live-Pfad zusammenführen

Artikel 8 · Serie: Einstieg in n8n
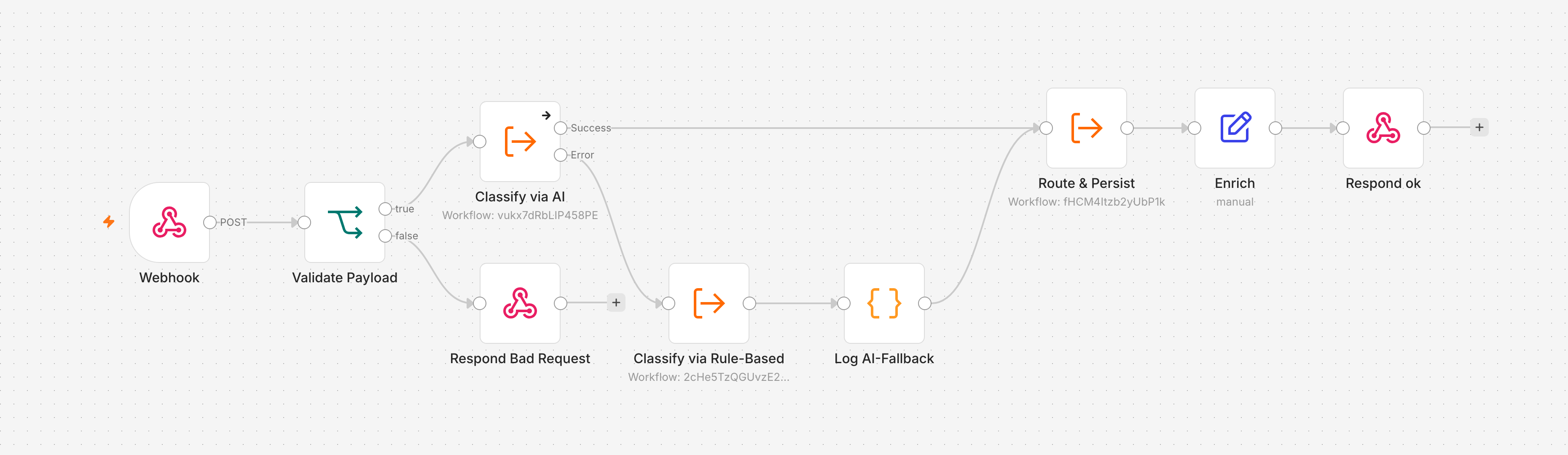
Nach Artikel 7 ist der Workflow produktionsreif, aber gespalten. Es gibt zwei Eingänge: den regelbasierten /ticket-ingest aus den frühen Artikeln, der ein Ticket per Keyword-Code einsortiert und danach endet, und die AI-Klassifikation aus Artikel 6, die über einen eigenen Webhook ein lokales Sprachmodell befragt und in die Routing-Pipeline mündet. Zwei Wege, zwei Klassifikationsarten, und nur der AI-Weg erreicht Routing und Persistierung. Dieser Artikel führt beide zu der einen Pipeline zusammen, die ADR 002 von Anfang an vorgesehen hat: ein Eingang, die AI als primäre Klassifikation, der regelbasierte Classifier als Fallback, ein gemeinsames Routing.
Der Code zu diesem Artikel liegt auf Codeberg, Tag v0.8: codeberg.org/rotecodefraktion/n8n-einstieg.
Klassifikation als austauschbare Stufe
Der Leitgedanke hinter der Zusammenführung ist eine Trennung von Zuständigkeiten. Der Eingang nimmt Tickets an, validiert sie und reicht sie weiter. Das Routing entscheidet anhand von Kategorie und P1-Verdacht, was mit dem Ticket geschieht. Dazwischen sitzt die Klassifikation, und die ist im Idealfall eine Blackbox: Sie bekommt einen normalisierten Text und gibt ein strukturiertes Ergebnis zurück. Ob dahinter ein Sprachmodell, ein Keyword-Matcher oder später ein Verbund mehrerer Backends steckt, darf den Eingang und das Routing nicht interessieren.
n8n macht diese Trennung über Sub-Workflows greifbar. Ein Workflow mit einem Execute Workflow Trigger definiert Eingabefelder und Rückgabewerte und lässt sich von einem anderen Workflow wie eine Funktion aufrufen. Genau diese Eigenschaft nutzt die Zusammenführung: Der Eingang ruft die Klassifikation als Sub-Workflow auf, statt sie inline zu enthalten. Damit wird die Klassifikationsstufe austauschbar, ohne den Eingang anzufassen.
Vom Keyword-Code zur AI-Klassifikation
Der bisherige /ticket-ingest rief einen Sub-Workflow auf, der die Kategorie über Keyword-Matching bestimmte. Der Umbau ersetzt diesen Aufruf durch einen Execute-Workflow-Node, der die AI-Klassifikation aufruft, den v0.8 OpenAI Classifier. Der Name trägt das OpenAI-Erbe, weil der Node-Typ lmChatOpenAi heißt, aber das Backend ist lokal. Als Default läuft Ollama mit qwen2.5:7b, der reproduzierbare Pfad aus Artikel 6: ein ollama pull qwen2.5:7b reicht, kein selbstgebauter Gateway nötig.
Hier lohnt ein Blick auf die Credential. Der OpenAI-Chat-Model-Node spricht eine OpenAI-kompatible API, und welche, entscheidet allein die Base-URL in der Credential. Eine Credential „Ollama lokal" zeigt auf http://host.docker.internal:11434/v1, eine zweite „Hummingbird MLX" auf den MLX-Gateway. Das Modell-Feld qwen2.5:7b ist nur ein Label; was tatsächlich antwortet, hängt an der Credential. Diese Austauschbarkeit auf Credential-Ebene ist die Vorstufe zum Round-Robin in Artikel 9. Für die Zusammenführung gilt: ein Backend, Ollama, reproduzierbar.
Der Aufruf bekommt die normalisierten Felder als Eingaben, id, subject, body, language, und gibt ein output-Objekt mit category, confidence, language, p1_suspected und p1_reason zurück. Auf dem Erfolgspfad reicht der Eingang dieses output direkt an die gemeinsame Routing-Pipeline weiter.
Warum der interne Fallback weichen muss
Der AI-Classifier aus Artikel 6 und 7 hatte am Basic LLM Chain ein On Error auf Continue (using error output). Fiel das Modell aus, brach der Workflow nicht ab, sondern lief in einen internen Zweig, der das Ticket still als sonstiges einsortierte. Das war für sich genommen sinnvoll: Der Ticket-Fluss sollte nicht abreißen, nur weil ein Modell mal weg ist.
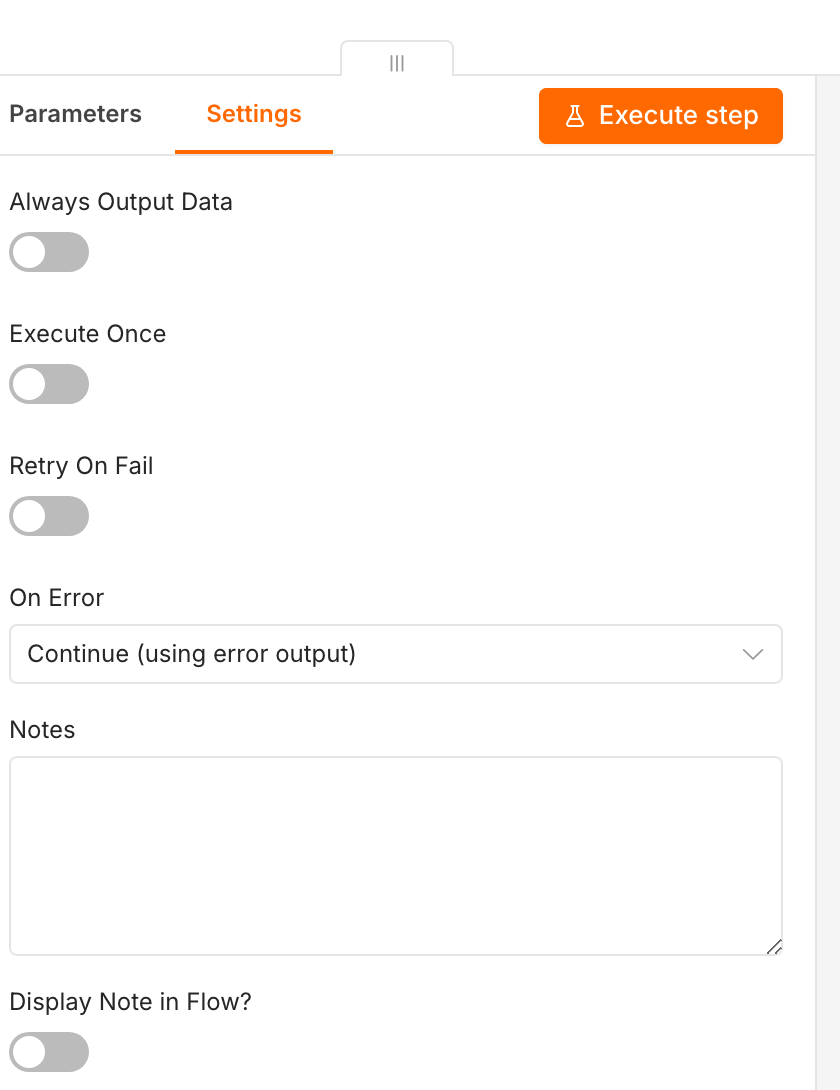
Für die Zusammenführung ist genau dieser interne Fallback ein Problem. Solange der Classifier seinen Ausfall selbst abfängt, scheitert der Execute-Workflow-Aufruf nie. Der Eingang sieht immer einen Erfolg und kann nie auf einen Fallback ausweichen. Das Fehler-Handling muss deshalb aus dem Classifier heraus und in den Eingang hinein wandern. Der Classifier scheitert künftig echt, wenn das Modell nicht antwortet oder ungültiges JSON liefert, und der Eingang entscheidet, was dann passiert.
Im Eingang sieht das so aus: Der Execute-Workflow-Node Classify via AI bekommt sein On Error auf Continue (using error output). Sein regulärer Ausgang führt auf den Erfolgspfad, sein Fehlerausgang in einen zweiten Execute-Workflow-Node, Classify via Rule-Based, der den regelbasierten Sub-Classifier aus Artikel 4 aufruft. Damit ist die Architektur umgekehrt: Nicht der Classifier kaschiert seinen Ausfall, sondern der Eingang fängt ihn ab und schaltet auf eine zweite, unabhängige Klassifikation um.
Der regelbasierte Classifier ist kein Notnagel
Es liegt nahe, den Keyword-Classifier als schlechtere AI abzutun. Das verfehlt seinen Zweck. Er ist ein deterministischer Fallback ohne externe Abhängigkeit. Wenn das Modell weg ist, ist eine Keyword-basierte Einordnung besser als gar keine, und vor allem besser als ein stilles sonstiges für jedes Ticket. Der regelbasierte Pfad braucht weder Netzwerk noch Modellserver, er läuft in Millisekunden und liefert ein nachvollziehbares Ergebnis. Genau deshalb steht er als bewusste zweite Schicht hinter dem Modell.
Dass diese zweite Schicht keine Theorie ist, zeigte sich beim Testen. qwen2.5:7b lieferte für ein Ticket ein an sich korrektes Ergebnis, formulierte die Begründung aber als "p1_reason": "Produktivausfall (...)" mit einem geraden Anführungszeichen mitten im Freitext. Damit endete der JSON-String zu früh, der Structured Output Parser scheiterte, und auch der nachgeschaltete Output-Fixing-Parser brachte es nicht gerade. Der AI-Aufruf scheiterte also an einem Formatierungsdetail des Modells, nicht an einem Ausfall. Der regelbasierte Fallback fing genau das ab. Ein kleines lokales Modell, das gelegentlich ungültiges JSON produziert, ist kein Sonderfall, sondern der Normalbetrieb, und damit das stärkste Argument für eine deterministische zweite Schicht.
Die Lehre für den Prompt: Das Freitextfeld p1_reason bekam die explizite Anweisung, keine Anführungszeichen zu enthalten. Danach formulierte das Modell die Begründung mit Klammern, und das JSON blieb parsebar. Solche Härtungen am Prompt sind der Preis für strukturierte Ausgaben aus kleinen Modellen.
Ein Rückgabe-Schema für beide Pfade
Die dritte und subtilste Falle steckt im Datenfluss. Die gemeinsame Routing-Pipeline ist selbst ein Sub-Workflow und erwartet definierte Eingaben: ein output-Objekt mit category, confidence, language, p1_suspected, p1_reason, dazu den pipelineInput für die Sprach-Erkennung und die priority. Ihr erster Code-Node liest $json.output.category. Steht dort kein output, bricht die Pipeline mit Cannot read properties of undefined ab.
Der AI-Classifier liefert dieses output-Objekt von sich aus. Der regelbasierte Classifier nicht: Er gibt ein flaches Objekt mit category, scores und match_count zurück, ganz ohne output-Hülle und ohne confidence oder p1_suspected. Würde der Fallback-Zweig dieses flache Ergebnis unverändert weiterreichen, käme die Pipeline an genau dieser Stelle zu Fall, obwohl der Fallback formal funktioniert hat.
Die Lösung sitzt im Fallback-Zweig: Ein Code-Node verpackt das flache Rule-Based-Ergebnis in dieselbe output-Form, die der AI-Pfad liefert. Dieser Node ist zugleich die Stelle, an der die Degradation beobachtbar wird, wie in Artikel 7 begonnen.
// Mode: Run Once for Each Item
console.log(JSON.stringify({
marker: 'n8n-ai-fallback',
backend: 'ollama',
ticketId: $json.id ?? $('Webhook').item.json.body?.id ?? null,
workflowName: $workflow.name,
reason: 'AI classifier failed, rule-based fallback',
timestamp: new Date().toISOString(),
}));
const r = $input.item.json;
return { json: { output: {
category: r.category ?? 'sonstiges',
confidence: 0,
language: r.language ?? 'unknown',
p1_suspected: false,
p1_reason: 'rule-based fallback',
} } };
Die confidence: 0 ist Absicht. Sie signalisiert dem Routing und jeder späteren Auswertung, dass dieses Ergebnis aus dem Fallback stammt und nicht aus dem Modell. Der Marker n8n-ai-fallback, in Artikel 7 noch im internen Classifier-Zweig, wandert mit dieser Umkehr an seinen logischen Ort: in den Eingang, dorthin, wo die Entscheidung „AI degradiert, Rule-Based übernimmt" tatsächlich fällt.
Ein Stolperstein aus Artikel 7, der hier wieder zuschlägt
Beim Testen lief eine Korrektur zunächst ins Leere, und der Grund ist derselbe wie in Artikel 7: das Save-vs-Publish-Modell aus n8n 2.0. Eine Änderung am Code eines Nodes wird nicht automatisch produktiv. Production-Executions laufen weiter gegen die zuletzt published Version, während der Editor schon die korrigierte Draft zeigt. Wer einen Code-Node anpasst, muss explizit publishen (Shift + P), sonst feuert in Production die alte Logik. Bei einem Fallback-Zweig fällt das besonders spät auf, weil er nur im Ausfall läuft. Diese Trennung ist kein Detail am Rande, sie ist die häufigste Ursache für „aber im Editor sieht es doch richtig aus".
End-to-End- und Fallback-Test
Zwei Tests sichern die Zusammenführung ab. Der erste schickt ein gültiges Ticket gegen den Eingang und prüft, dass die AI klassifiziert und die Pipeline routet:
curl -sk -X POST https://localhost/webhook/ticket-ingest \
-H "Content-Type: application/json" \
-H "X-Ingest-Token: <token>" \
-d '{"id":"E2E-001","subject":"SM50 work process restart",
"body":"All work processes in PRIV mode, users cannot log on.",
"priority":"high","language":"en"}'
Die Antwort kommt mit HTTP 200 und einem vollen Ergebnis: category: sap-basis, confidence: 1, p1_suspected: true, geroutet auf queue-sap-basis und an den PagerDuty-Demo-Endpunkt gemeldet. Der AI-Pfad ist gelaufen, das Routing hat gegriffen.
Der zweite Test stoppt Ollama und schickt dasselbe Muster erneut:
# Ollama stoppen, dann erneut triggern
curl -sk https://localhost/webhook/ticket-ingest -H "X-Ingest-Token: <token>" -d '{...}'
# Marker auf der Standardausgabe
docker logs --since 1m docker-n8n-1 | grep n8n-ai-fallback
Jetzt scheitert der Classify via AI-Aufruf echt, der Eingang schaltet auf den regelbasierten Classifier, der Marker n8n-ai-fallback erscheint auf der Standardausgabe mit der Ticket-ID, und das Ticket wird trotzdem geroutet, mit confidence: 0 als Fallback-Signatur. Der Webhook antwortet weiterhin mit HTTP 200, und die Execution des Eingangs gilt als success. Bemerkenswert dabei: Der v0.7-error-handler aus dem letzten Artikel feuert beim AI-Ausfall weiterhin mit, denn der Sub-Workflow Classify via AI ist tatsächlich gescheitert. Die Degradation bleibt also über zwei Kanäle sichtbar, über den Error-Workflow und über den Fallback-Marker, während der Ticket-Fluss unangetastet bleibt.
Was als Nächstes kommt
Die Klassifikation ist jetzt eine austauschbare Stufe mit einem deterministischen Fallback dahinter. Was fehlt, ist echte Redundanz auf der AI-Ebene selbst: Ein zweites Modell-Backend, das übernimmt, bevor der regelbasierte Notausgang greift. Aus einem AI-Backend wird im nächsten Artikel ein Verbund aus zweien, Ollama und der Hummingbird-MLX-Gateway, über Round-Robin verteilt und mit echtem Failover (Artikel 9). Der regelbasierte Classifier rückt damit eine Schicht nach hinten: vom ersten Fallback zum letzten.