Zwei Modelle, ein Eingang — Round-Robin und Failover über lokale AI-Backends

Artikel 9 · Serie: Einstieg in n8n
Am Ende von Artikel 8 hat der Eingang eine AI-Klassifikation mit einem regelbasierten Fallback dahinter. Das fängt einen Modell-Ausfall ab, aber grob: Fällt das eine Backend aus, klassifiziert sofort der Keyword-Matcher, mit confidence: 0. Eine Stufe dazwischen fehlt. Dieser Artikel baut sie ein, indem aus einem AI-Backend zwei werden: ein lokales Ollama-Modell und der Hummingbird-MLX-Gateway, im Normalbetrieb über Round-Robin verteilt, bei Ausfall mit echtem Failover aufeinander. Der regelbasierte Classifier rückt damit eine Schicht nach hinten, vom ersten Fallback zum letzten, der erst greift, wenn beide AI-Backends tot sind.
Der Code zu diesem Artikel liegt auf Codeberg, Tag v0.9: codeberg.org/rotecodefraktion/n8n-einstieg.
Graceful Degradation ist nicht Failover
Artikel 7 hat den stillen Modell-Ausfall beobachtbar gemacht, Artikel 8 den regelbasierten Fallback in den Eingang verlegt. Beides ist graceful degradation: Wenn die AI weg ist, läuft der Ticket-Fluss mit einer schlechteren, aber funktionierenden Klassifikation weiter. Failover ist etwas anderes. Failover heißt, ein zweites gleichwertiges Backend übernimmt, ohne Qualitätsverlust, und der Notausgang bleibt zu, solange irgendein AI-Backend antwortet. Der Unterschied ist für den Betrieb erheblich: Bei einem einzelnen Gateway-Neustart will man keine Stunde lang alle Tickets in einer Keyword-Klassifikation sammeln, wenn nebenan ein zweites Modell bereitsteht.
Dafür braucht es zwei Dinge: ein zweites AI-Backend, das dasselbe Rückgabe-Schema liefert, und einen Dispatcher, der die Last verteilt und bei Ausfall umschaltet.
Das zweite Backend spricht Anthropic, nicht OpenAI
Das erste Backend ist der v0.8 OpenAI Classifier aus Artikel 8: ein OpenAI-Chat-Model-Node, der über das Credential Ollama lokal gegen qwen2.5:7b läuft. Für das zweite habe ich diesen Classifier dupliziert und auf den Hummingbird-MLX-Gateway umgestellt. Dabei lauert die erste Überraschung: Der Gateway spricht nicht die OpenAI-, sondern die Anthropic-API. Beide Chat-Model-Nodes im Duplikat mussten deshalb von „OpenAI Chat Model" auf „Anthropic Chat Model" wechseln, mit einem Anthropic-Credential, dessen Base-URL auf den Gateway zeigt (http://host.docker.internal:8080). Welche API gesprochen wird, entscheidet allein das Credential, nicht der Node-Name oder das Modell-Feld.
Die zweite Überraschung steckt im Modell. Der Gateway bedient mlx-community/Qwen3-8B-4bit, und Qwen3 läuft im Thinking-Mode: Es schiebt seinen Gedankengang als Fließtext vor die eigentliche Antwort. Für eine Chat-Anwendung ist das nett, für einen Structured Output Parser ist es tödlich, denn vor dem JSON steht ein Absatz Prosa. Die Lösung ist ein /no_think ganz am Anfang des System-Prompts. Damit unterdrückt Qwen3 den Reasoning-Block und liefert direkt sauberes JSON. Der Versuch, das über den API-Parameter chat_template_kwargs: {enable_thinking: false} zu erreichen, scheitert, weil der Gateway ihn nicht durchreicht, der Prompt-Prefix wirkt dagegen zuverlässig.
Das ist der eigentliche Lehrsatz dieser Stufe: Zwei Backends sind nicht zwei austauschbare Kästen. qwen2.5 braucht kein /no_think, Qwen3 schon. Wer Redundanz über verschiedene Modelle baut, härtet jeden Prompt gegen die Eigenheiten seines Backends.
Round-Robin über staticData
Der Dispatcher beginnt mit der Frage, welches Backend ein Ticket zuerst sieht. Statt es fest zu verdrahten oder vom Zufall abhängig zu machen, verteilt ein Code-Node die Last reihum. n8n stellt dafür $getWorkflowStaticData('global') bereit, einen kleinen, über Läufe hinweg persistenten Speicher pro Workflow. Ein Zähler darin, modulo zwei, bestimmt die Reihenfolge:
// Mode: Run Once for Each Item
const s = $getWorkflowStaticData('global');
s.rr = (s.rr || 0) + 1;
const OLLAMA = 'vukx7dRbLIP458PE'; // v0.8 OpenAI Classifier
const MLX = 'FDCjcytGNeO3ODH6'; // v0.9 MLX Classifier
const order = (s.rr % 2 === 0) ? [OLLAMA, MLX] : [MLX, OLLAMA];
const b = $json.body;
return { json: {
id: b.id, subject: b.subject, body: b.body, language: b.language,
priority: b.priority ?? '',
primaryId: order[0], secondaryId: order[1],
primaryBackend: order[0] === OLLAMA ? 'ollama' : 'mlx',
secondaryBackend: order[1] === OLLAMA ? 'ollama' : 'mlx',
} };
Die Node gibt nicht nur die normalisierten Ticket-Felder weiter, sondern auch primaryId und secondaryId, die beiden Backend-Workflows in der für diesen Lauf gewählten Reihenfolge. Der secondaryId ist immer das jeweils andere Backend als primaryId. Eine Anmerkung zum staticData: Der Speicher wird nur bei aktiven, produktiven Läufen persistiert, manuelle Editor-Läufe zählen den Zähler nicht hoch. Für die Lastverteilung im Betrieb genügt das.
Die Failover-Kaskade mit dynamischer Workflow-ID
Hier zahlt sich die Entscheidung aus Artikel 8 aus, die Klassifikation als Sub-Workflow zu kapseln. Der Dispatcher ruft nicht zwei fest verdrahtete Backends auf, sondern zweimal denselben Execute-Workflow-Node-Typ, dessen Ziel-Workflow als Ausdruck aus dem Ticket kommt.
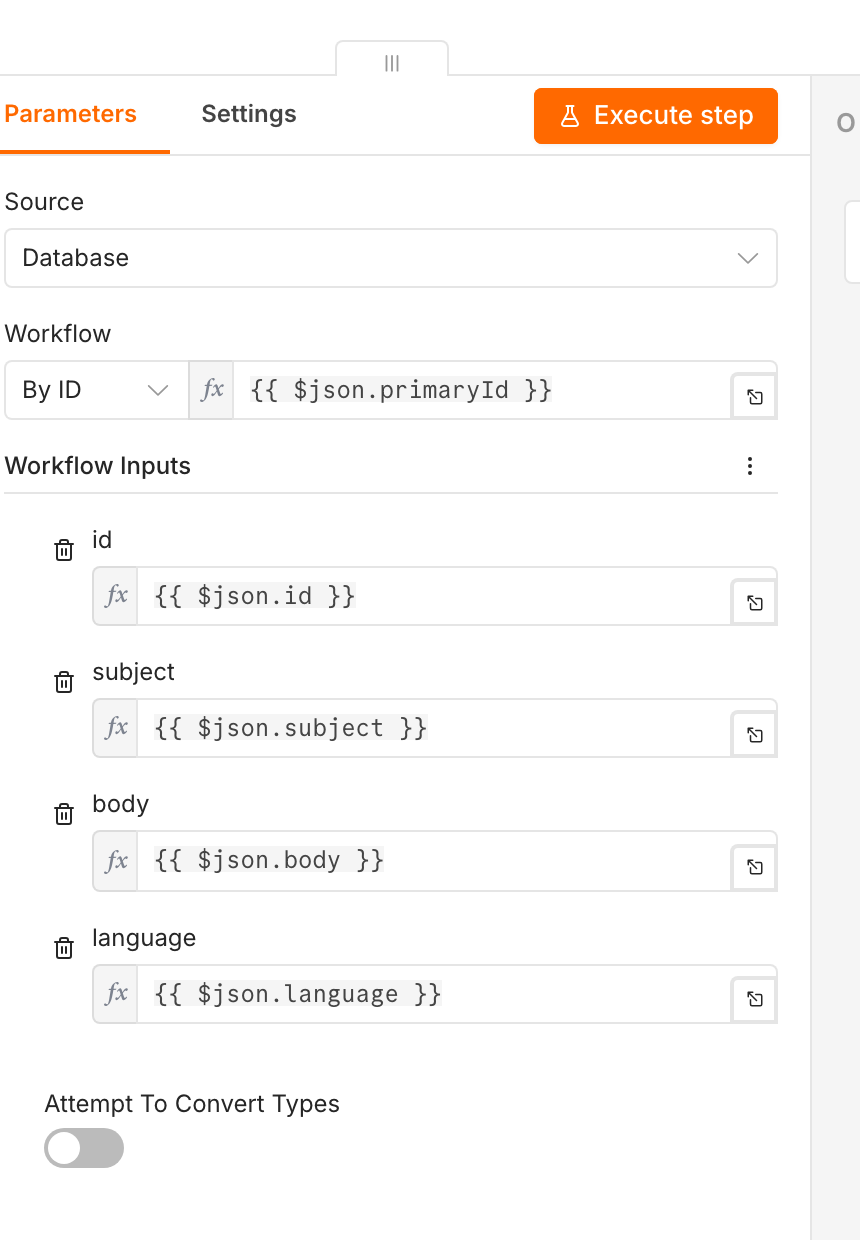
Der erste Execute-Node, Classify via AI (primary), bekommt seine Workflow-ID aus {{ $json.primaryId }}, der zweite, Classify via AI (secondary), aus {{ $json.secondaryId }}. Beide stehen auf On Error: Continue (using error output). Damit ergibt sich die Kaskade:
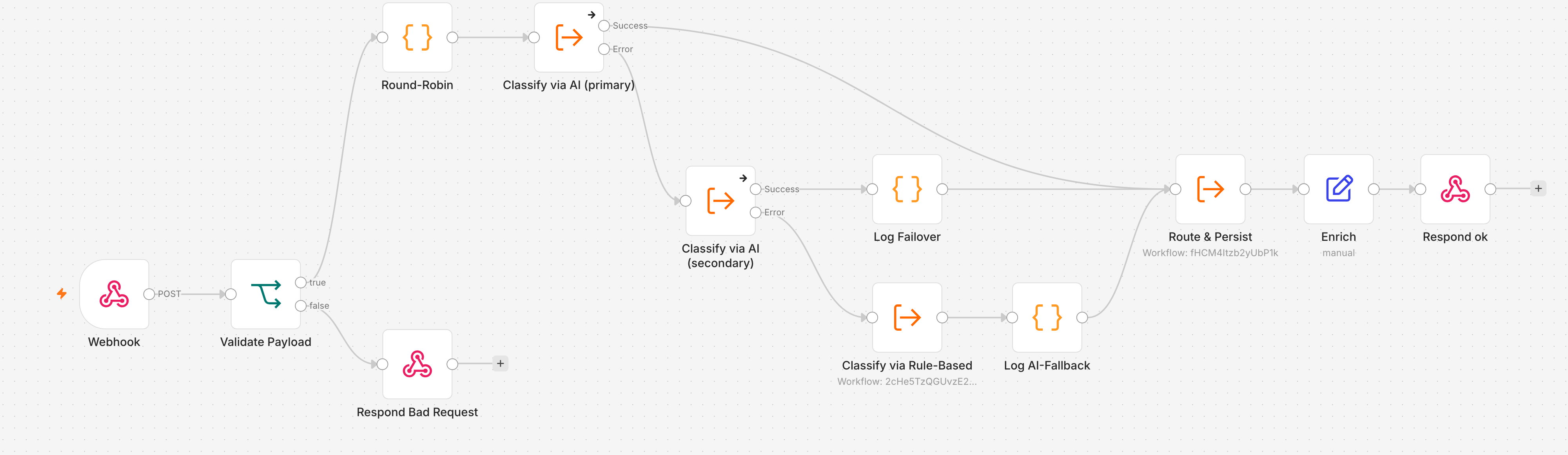
Der primäre Aufruf führt bei Erfolg direkt ins gemeinsame Routing. Scheitert er, läuft sein Fehlerausgang in den sekundären Aufruf, der das andere Backend anspricht. Erst wenn auch der scheitert, greift der regelbasierte Classifier aus Artikel 4, gefolgt vom Marker und dem Routing. Ein Detail beim Bau: Damit die Eingabe-Maske des Execute-Nodes die Felder id, subject, body, language anzeigt, wählt man zunächst einen konkreten Workflow aus der Liste, mappt die Felder, und stellt erst danach die Quelle auf „By ID" mit dem Ausdruck um, das Mapping bleibt erhalten.
Die Backend-Namen für die Marker holt die Kaskade per $('Round-Robin').item.json zurück. Diese paired-item-Referenz trägt durch die Execute-Aufrufe hindurch, auch wenn das Backend dazwischen gescheitert ist.
Drei Stufen der Beobachtbarkeit
Aus zwei Backends und einem Notausgang ergeben sich drei Betriebszustände, und jeder bekommt seine eigene Spur. Im Normalbetrieb läuft genau ein Backend, es gibt nichts zu melden, kein Marker. Bei einem Einzelausfall übernimmt das zweite Backend, und das ist ein Ereignis, das man sehen will. Auf dem Erfolgspfad des sekundären Aufrufs, der nur nach einem primären Fehlschlag überhaupt läuft, sitzt deshalb ein Code-Node Log Failover:
// Mode: Run Once for Each Item
const rr = $('Round-Robin').item.json;
console.log(JSON.stringify({
marker: 'n8n-ai-failover',
failedBackend: rr.primaryBackend,
servedBackend: rr.secondaryBackend,
ticketId: rr.id ?? null,
workflowName: $workflow.name,
reason: 'primary AI backend failed, secondary took over',
timestamp: new Date().toISOString(),
}));
return $input.item;
Der dritte Zustand ist der Doppelausfall. Der Log AI-Fallback-Node aus Artikel 8 bleibt erhalten, aber statt eines fest verdrahteten Backend-Namens schreibt er jetzt beide ausgefallenen Backends in den Marker:
const rr = $('Round-Robin').item.json;
console.log(JSON.stringify({
marker: 'n8n-ai-fallback',
failedBackends: [rr.primaryBackend, rr.secondaryBackend],
ticketId: rr.id ?? $json.id ?? null,
workflowName: $workflow.name,
reason: 'both AI backends failed, rule-based fallback',
timestamp: new Date().toISOString(),
}));
// ... Rule-Based-Ergebnis in das output-Schema wrappen, confidence: 0
Über Alloy landen beide Marker in Loki. n8n-ai-failover zeigt, wann welches Backend wackelte, ohne dass die Klassifikation litt, n8n-ai-fallback zeigt den seltenen Fall, in dem beide weg waren. Hinzu kommt, dass der globale Error-Workflow aus Artikel 7 bei jedem Backend-Fehler ohnehin mitfeuert, der Sub-Workflow ist ja echt gescheitert. Ein Einzelausfall ist damit über zwei Kanäle sichtbar und stört den Ticket-Fluss trotzdem nicht.
Verifikation: Round-Robin, Failover, Doppelausfall
Drei Tests sichern die Stufe ab. Der erste schickt mehrere Tickets bei beiden laufenden Backends und liest aus den Executions, welcher Classifier lief:
| Ticket | Backend (Execution) |
|---|---|
| 1 | MLX |
| 2 | Ollama |
| 3 | MLX |
| 4 | Ollama |
Saubere Alternation, je ein Backend pro Lauf. Nebenbei verrät die Antwort das Backend: qwen2.5 gibt für den Produktivausfall confidence: 1, Qwen3 0.95.
Der zweite Test stoppt Ollama und schickt erneut. Wo MLX primär ist, klassifiziert es direkt, wo Ollama primär ist, scheitert der Aufruf und MLX übernimmt. Jedes Ticket bekommt weiter eine echte AI-Klassifikation, der regelbasierte Fallback bleibt unberührt, und im Log steht der Failover-Marker:
{"marker":"n8n-ai-failover","failedBackend":"ollama","servedBackend":"mlx","ticketId":"..."}
Der dritte Test stoppt beide. Jetzt scheitern beide Aufrufe, der regelbasierte Classifier greift, das Ticket wird mit confidence: 0 geroutet, HTTP 200, und der Fallback-Marker führt beide ausgefallenen Backends:
{"marker":"n8n-ai-fallback","failedBackends":["mlx","ollama"],"ticketId":"..."}
Übergang zu Artikel 10
Die Klassifikationsstufe ist jetzt resilient: Last verteilt, Einzelausfall abgefangen, Notausgang nur bei Totalausfall. Damit ist die AI-Seite der Pipeline abgeschlossen. Der nächste Artikel verlässt die Klassifikation und wendet sich der Persistierung zu, die bisher nur eine Demo-Gabel war: die SAP-Brücke über OData und HTTP, und wo das native AIF des SAP-Standards komplementär bleibt (Artikel 10).
Zweites Backend ohne MLX-Gateway: ein zweites Ollama-Modell
Das Round-Robin braucht zwei Backends, aber nicht zwingend den Hummingbird-MLX-Gateway. Wer den Swift-Gateway nicht bauen will, nimmt als zweites Backend ein zweites Ollama-Modell. Voraussetzung ist nur ein weiterer Pull:
ollama pull llama3.1:8b
Statt des v0.9 MLX Classifier mit Anthropic-Node wird der Sub-Workflow dann mit einem zweiten OpenAI-Chat-Model-Node gebaut, Credential Ollama lokal, Modell llama3.1:8b. Das /no_think entfällt, weil llama3.1 keinen Thinking-Mode hat, dafür lohnt ein Blick auf die JSON-Formatierung, die zwischen Modellen variiert. Die Dispatcher-Logik bleibt identisch: Round-Robin und Failover interessiert nicht, welche zwei Backends dahinterstehen, nur dass es zwei sind und beide dasselbe Schema liefern.