Streaming — Tokens Flow as They Are Born

On an M3 Pro, an 8B model takes between 2 and 10 seconds to produce a complete response. Without streaming, the client waits for the last token before seeing anything. With streaming, the first token appears after 100-200 milliseconds. Claude Code, Cursor, and all other coding tools insist on stream: true, so we implement it now. Both endpoints — Anthropic and OpenAI — get their respective event-stream variants; a shared backend stream provides the deltas.
The Two SSE Formats
Server-Sent Events share the same wire format: text/event-stream as Content-Type, data: lines terminated with \n\n. The protocols differ in what those lines contain.
OpenAI sends a sequence of JSON chunks, terminated with the data: [DONE]\n\n sentinel:
data: {"id":"chatcmpl-abc","choices":[{"delta":{"role":"assistant"},"finish_reason":null}],...}
data: {"id":"chatcmpl-abc","choices":[{"delta":{"content":"Hello"},"finish_reason":null}],...}
data: {"id":"chatcmpl-abc","choices":[{"delta":{},"finish_reason":"stop"}],...}
data: [DONE]
Anthropic sends seven different event types in a fixed order. Each event has an event: line before the data: line:
| Order | Event | Meaning |
|---|---|---|
| 1 | message_start | Empty message envelope with ID and model |
| 2 | content_block_start | Block index 0, empty text block |
| 3..N | content_block_delta | One token fragment per event |
| N+1 | content_block_stop | Block 0 complete |
| N+2 | message_delta | stop_reason and final token counts |
| N+3 | message_stop | Stream finished |
mlx_lm.server speaks only OpenAI format. We produce the Anthropic events ourselves in the gateway from the OpenAI chunks.
mlx_lm.server Streaming
A direct test against the backend shows the format:
curl -s -N -X POST localhost:8081/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mlx-community/Qwen3-8B-4bit",
"stream": true,
"max_tokens": 50,
"messages": [{"role": "user", "content": "say hi /no_think"}]
}'
mlx_lm.server delivers one chunk per token and terminates with data: [DONE]. Streaming requires no configuration on the backend side; stream: true in the request body is all it needs.
On Linux and Windows the same applies to Ollama: the SSE format is identical. Anyone starting the gateway with --mlx-url http://localhost:11434 can use the curl examples in this section unchanged — only the port number differs.
The -N flag disables curl’s internal output buffer. Without it, curl holds all incoming data until a buffer fills, which destroys the token-by-token effect. For programmatic use, -s -N is the right combination: no progress output, no buffer delay.
MLXClient.completeStream
In MLXClient.swift we add a second public method that returns not a (text, inputTokens, outputTokens) tuple but an AsyncThrowingStream<StreamDelta, Error>:
/// Streaming variant. Returns an AsyncThrowingStream of text deltas
/// from the model. The stream finishes after the [DONE] sentinel
/// or when the connection is cancelled.
nonisolated func completeStream(
messages: [ChatMessage],
model: String,
maxTokens: Int = 1024,
temperature: Double = 1.0
) -> AsyncThrowingStream<StreamDelta, Error> {
AsyncThrowingStream { continuation in
let task = Task {
do {
try await self.runStream(
messages: messages,
model: model,
maxTokens: maxTokens,
temperature: temperature,
continuation: continuation
)
continuation.finish()
} catch is CancellationError {
continuation.finish()
} catch {
continuation.finish(throwing: error)
}
}
continuation.onTermination = { _ in
task.cancel()
}
}
}
struct StreamDelta: Sendable {
let text: String
let finishReason: String?
let inputTokens: Int?
let outputTokens: Int?
}
Two details matter here.
nonisolated allows the method to be called outside the actor context. Route handlers do not run inside the MLXClient actor, and the return type (AsyncThrowingStream) contains no actor-isolated values — the compiler accepts nonisolated without a concurrency violation.
continuation.onTermination receives a closure that the AsyncStream calls when the consumer cancels or finishes. We cancel the inner task that holds the URLSession connection. The backend stops generating; no wasted compute.
The SSE Parser in runStream
The SSE parser runs in the private method runStream. The core is URLSession.bytes(for:), which returns an AsyncSequence<UInt8, Error> over the response bytes. From this we read line by line:
private func runStream(
messages: [ChatMessage],
model: String,
maxTokens: Int,
temperature: Double,
continuation: AsyncThrowingStream<StreamDelta, Error>.Continuation
) async throws {
guard let url = URL(string: "\(baseURL)/v1/chat/completions") else {
throw MLXError.invalidURL(baseURL)
}
let body = ChatCompletionRequest(
model: model, messages: messages, maxTokens: maxTokens,
temperature: temperature, topP: nil, stream: true,
stop: nil, presencePenalty: nil, frequencyPenalty: nil, user: nil
)
var request = URLRequest(url: url)
request.httpMethod = "POST"
request.setValue("application/json", forHTTPHeaderField: "Content-Type")
request.setValue("text/event-stream", forHTTPHeaderField: "Accept")
request.httpBody = try JSONEncoder().encode(body)
let (bytes, response): (URLSession.AsyncBytes, URLResponse)
do {
(bytes, response) = try await session.bytes(for: request)
} catch let urlError as URLError {
throw MLXError.backendUnavailable(urlError.localizedDescription)
}
guard let http = response as? HTTPURLResponse, http.statusCode == 200 else {
throw MLXError.inferenceError(0, "Non-200 response")
}
let decoder = JSONDecoder()
for try await line in bytes.lines {
try Task.checkCancellation()
guard line.hasPrefix("data:") else { continue }
let payload = line.dropFirst("data:".count).trimmingCharacters(in: .whitespaces)
if payload.isEmpty || payload == "[DONE]" { break }
guard let data = payload.data(using: .utf8),
let chunk = try? decoder.decode(ChatCompletionStreamChunk.self, from: data),
let choice = chunk.choices.first
else { continue }
let deltaText = choice.delta.content ?? choice.delta.reasoning ?? ""
continuation.yield(StreamDelta(
text: deltaText,
finishReason: choice.finishReason,
inputTokens: chunk.usage?.promptTokens,
outputTokens: chunk.usage?.completionTokens
))
}
}
The bytes.lines property handles newline splitting and delivers UTF-8 strings directly. We only care about lines that start with data: — all others (empty lines, any event: lines from mlx_lm.server) are skipped. The [DONE] sentinel is treated as a clean end-of-stream with break rather than an error. Chunks that fail to decode are skipped silently, guarding against unknown keep-alive or diagnostic events the backend might emit.
Task.checkCancellation() inside the loop ensures that a cancellation signal takes effect immediately, not after waiting for the next token.
OpenAI Stream Output
In Streaming/StreamingResponses.swift we build two functions that consume a AsyncThrowingStream<StreamDelta, Error> and produce SSE bytes from it. Hummingbird’s ResponseBody(asyncSequence:) accepts an AsyncSequence<ByteBuffer, Error> and streams the bytes to the client.
private let sseHeaders: HTTPFields = [
.contentType: "text/event-stream",
.cacheControl: "no-cache",
]
func openAIStreamResponse(
deltas: AsyncThrowingStream<StreamDelta, Error>,
model: String
) -> Response {
let bytes = AsyncStream<ByteBuffer> { continuation in
let task = Task {
let id = "chatcmpl-" + String(UUID().uuidString.prefix(8).lowercased())
let created = Int(Date().timeIntervalSince1970)
let encoder = JSONEncoder()
var isFirstChunk = true
do {
for try await delta in deltas {
try Task.checkCancellation()
let role: ChatRole? = isFirstChunk ? .assistant : nil
isFirstChunk = false
let chunk = ChatCompletionStreamChunk(
id: id, object: "chat.completion.chunk",
created: created, model: model,
choices: [
ChatCompletionStreamChoice(
index: 0,
delta: ChatCompletionDelta(role: role, content: delta.text, reasoning: nil),
finishReason: delta.finishReason
)
],
usage: nil
)
try emitOpenAIChunk(chunk, encoder: encoder, into: continuation)
}
var done = ByteBufferAllocator().buffer(capacity: 16)
done.writeString("data: [DONE]\n\n")
continuation.yield(done)
continuation.finish()
} catch {
continuation.finish()
}
}
continuation.onTermination = { _ in task.cancel() }
}
return Response(status: .ok, headers: sseHeaders, body: .init(asyncSequence: bytes))
}
The first chunk of an OpenAI stream carries role: "assistant" in the delta per spec; all subsequent chunks contain only content. The isFirstChunk flag manages exactly that. The closing [DONE] sentinel is written directly as a raw string into the ByteBuffer — it is not JSON and needs no encoding.
Anthropic Stream Output
The Anthropic function is more involved because it emits seven different event types in a fixed order. We define small Encodable structs in Models/Anthropic.swift for each event:
struct AnthropicStreamContentBlockDelta: Encodable {
let type = "content_block_delta"
let index: Int
let delta: AnthropicTextDelta
}
struct AnthropicTextDelta: Encodable {
let type = "text_delta"
let text: String
}
The main function in StreamingResponses.swift:
func anthropicStreamResponse(
deltas: AsyncThrowingStream<StreamDelta, Error>,
model: String
) -> Response {
let bytes = AsyncStream<ByteBuffer> { continuation in
let task = Task {
let id = "msg_" + String(UUID().uuidString
.replacingOccurrences(of: "-", with: "").lowercased().prefix(24))
let encoder = JSONEncoder()
var outputTokens = 0
var inputTokens = 0
var stopReason = "end_turn"
do {
// 1. message_start
let start = AnthropicStreamMessageStart(
message: AnthropicStreamMessage(
id: id, content: [], model: model,
stopReason: nil, stopSequence: nil,
usage: AnthropicUsage(inputTokens: 0, outputTokens: 0)
)
)
try emit(event: "message_start", payload: start, encoder: encoder, into: continuation)
// 2. content_block_start
let blockStart = AnthropicStreamContentBlockStart(
index: 0,
contentBlock: AnthropicContentBlock(type: "text", text: "")
)
try emit(event: "content_block_start", payload: blockStart, encoder: encoder, into: continuation)
// 3..N content_block_delta
for try await delta in deltas {
try Task.checkCancellation()
if !delta.text.isEmpty {
let blockDelta = AnthropicStreamContentBlockDelta(
index: 0, delta: AnthropicTextDelta(text: delta.text)
)
try emit(event: "content_block_delta", payload: blockDelta, encoder: encoder, into: continuation)
}
if let r = delta.finishReason { stopReason = mapFinishReason(r) }
if let i = delta.inputTokens { inputTokens = i }
if let o = delta.outputTokens { outputTokens = o }
}
// 4–6. stop events + usage
try emit(event: "content_block_stop",
payload: AnthropicStreamContentBlockStop(index: 0),
encoder: encoder, into: continuation)
try emit(event: "message_delta",
payload: AnthropicStreamMessageDelta(
delta: AnthropicMessageDeltaInfo(stopReason: stopReason, stopSequence: nil),
usage: AnthropicUsage(inputTokens: inputTokens, outputTokens: outputTokens)
),
encoder: encoder, into: continuation)
try emit(event: "message_stop",
payload: AnthropicStreamMessageStop(),
encoder: encoder, into: continuation)
continuation.finish()
} catch {
continuation.finish()
}
}
continuation.onTermination = { _ in task.cancel() }
}
return Response(status: .ok, headers: sseHeaders, body: .init(asyncSequence: bytes))
}
mapFinishReason translates OpenAI finish reasons (stop, length) to Anthropic terminology (end_turn, max_tokens). The usage values accumulate across the delta loop and are emitted in message_delta once the backend has provided the final counts.
Route Branching
Both routes in Router+build.swift now return Response instead of the specific response structs. An if branch checks payload.stream == true:
router.post("v1/messages") { request, context -> Response in
let payload = try await request.decode(as: MessageRequest.self, context: context)
try validate(payload)
let messages = toOpenAIMessages(from: payload)
if payload.stream == true {
let deltas = mlxClient.completeStream(
messages: messages,
model: modelID,
maxTokens: payload.maxTokens,
temperature: payload.temperature ?? 1.0
)
return anthropicStreamResponse(deltas: deltas, model: modelID)
}
// Non-streaming path (unchanged)
let result = try await withMLXError {
try await mlxClient.complete(
messages: messages,
model: modelID,
maxTokens: payload.maxTokens,
temperature: payload.temperature ?? 1.0
)
}
let response = buildAnthropicResponse(
text: result.text, model: modelID,
inputTokens: result.inputTokens, outputTokens: result.outputTokens
)
return try response.response(from: request, context: context)
}
In the non-streaming path we convert MessageResponse manually: the ResponseGenerator protocol from Article 2 provides response(from:context:) that builds a Response from the struct.
The same pattern applies to /v1/chat/completions.
Task Cancellation
When a client disconnects mid-stream — Ctrl-C, connection reset, tool abort — Hummingbird/SwiftNIO cancels the response-write task. The signal propagates through the AsyncStream<ByteBuffer> consumer to its onTermination closure: we cancel the inner task holding the URLSession.AsyncBytes iteration. runStream throws the CancellationError, which completeStream treats as a clean stream end and closes the continuation cleanly.
The result: mlx_lm.server stops token generation as soon as the connection drops, because the HTTP connection to the backend is also closed. No process continues computing a response that nobody will read — this matters especially for long requests with thousands of output tokens.
In the following example we start a long request and abort it with Ctrl-C after one second:
curl -N -X POST localhost:8080/v1/messages \
-H "Content-Type: application/json" \
-d '{
"model": "mlx-community/Qwen3-8B-4bit",
"stream": true,
"max_tokens": 2048,
"messages": [{"role": "user", "content": "Explain Hummingbird in detail."}]
}'
^C
No error appears in the gateway log. The session closes cleanly, the task is torn down, and the model has stopped generating.
Testing with curl -N
The -N flag (alias --no-buffer) disables curl’s internal output buffer. Without it, curl holds output until the buffer is full:
# Anthropic endpoint, tokens visible one by one
curl -s -N -X POST localhost:8080/v1/messages \
-H "Content-Type: application/json" \
-d '{
"model": "mlx-community/Qwen3-8B-4bit",
"stream": true,
"max_tokens": 200,
"messages": [{"role": "user", "content": "Write a haiku about Swift. /no_think"}]
}'
Output excerpt:
event: message_start
data: {"type":"message_start","message":{...}}
event: content_block_start
data: {"type":"content_block_start","index":0,"content_block":{"type":"text","text":""}}
event: content_block_delta
data: {"type":"content_block_delta","index":0,"delta":{"type":"text_delta","text":"Code"}}
event: content_block_delta
data: {"type":"content_block_delta","index":0,"delta":{"type":"text_delta","text":" flows"}}
...
# OpenAI endpoint
curl -s -N -X POST localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mlx-community/Qwen3-8B-4bit",
"stream": true,
"max_tokens": 200,
"messages": [{"role": "user", "content": "Explain Structured Concurrency in two sentences. /no_think"}]
}'
Claude Code with Streaming
Claude Code sends stream: true automatically. Since Article 3 it has been talking to our gateway; since Article 4 the responses appear token by token, the way Claude.ai itself renders them:
export ANTHROPIC_BASE_URL=http://localhost:8080
claude
The difference is tangible. Instead of a pause followed by a block of text, the response builds up visibly. For longer code snippets or explanations, that is the difference between waiting and watching something being typed.
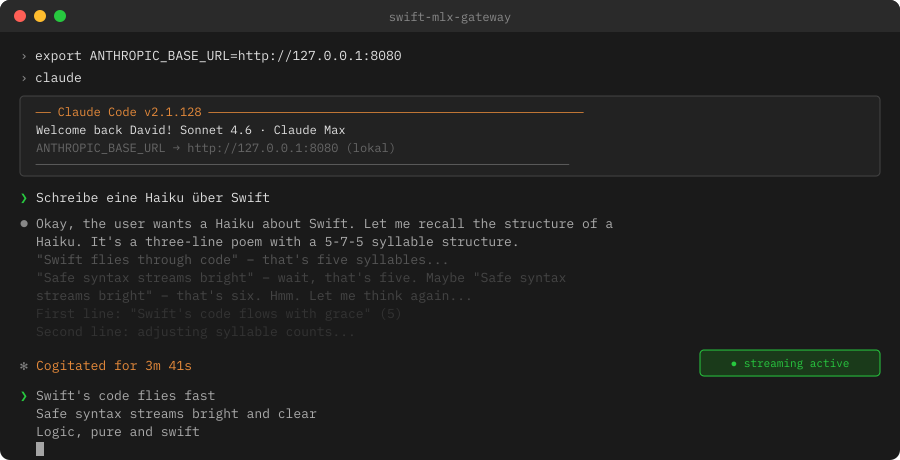
The Qwen3 reasoning trace is visible here — the model thinks out loud before producing the haiku. “Cogitated for 3m 41s” shows this was streaming over three minutes, not a blocking three-minute wait. For responses without the reasoning trace, append /no_think to the prompt.
Commit and Tag
git add .
git commit -m "article-04: Streaming via Server-Sent Events"
git tag article-04
git push origin main --tags
Five New Code Units, Both Endpoints Stream
| File | Change |
|---|---|
MLX/MLXClient.swift | completeStream + runStream + StreamDelta |
Models/Anthropic.swift | Stream event structs (6 new types) |
Models/OpenAI.swift | ChatCompletionStreamChunk, ChatCompletionStreamChoice, ChatCompletionDelta |
Router+build.swift | Stream branching in both routes |
Streaming/StreamingResponses.swift | New: anthropicStreamResponse and openAIStreamResponse |
The Codable types from Article 2 and the MLXClient from Article 3 remain unchanged. Streaming is not an extension of the existing types but a second signal path that transports the same data structures differently.
Article 5 extends the gateway with a Custom RequestContext: API-key authentication, rate limiting per token bucket, and spec-compliant error formats for both protocols.
Sources
- Anthropic Streaming Messages API, docs.anthropic.com
- OpenAI Chat Completions Streaming, platform.openai.com
- Server-Sent Events Spec, html.spec.whatwg.org
- URLSession.AsyncBytes, developer.apple.com
- AsyncThrowingStream, docs.swift.org
- Hummingbird ResponseBody(asyncSequence:), docs.hummingbird.codes