AI Classification Without the Cloud — the Ticket Workflow Gets a Brain

Article 6 · Series: Getting Started with n8n
The classifier from Article 4 assigns tickets using keyword matching. That works as long as the right words appear in the text, and breaks down for English tickets with variant spelling. Article 5 gave that classifier an authenticated entrance. In this article we replace the keyword matching with a language model that recognizes semantic proximity rather than exact character sequences. We build it twice, with two different local models, and at the end we measure whether the effort actually pays off compared to the rule-based approach.
The code for this article is on Codeberg, tag v0.6: codeberg.org/rotecodefraktion/n8n-einstieg.
Basic LLM Chain Instead of AI Agent
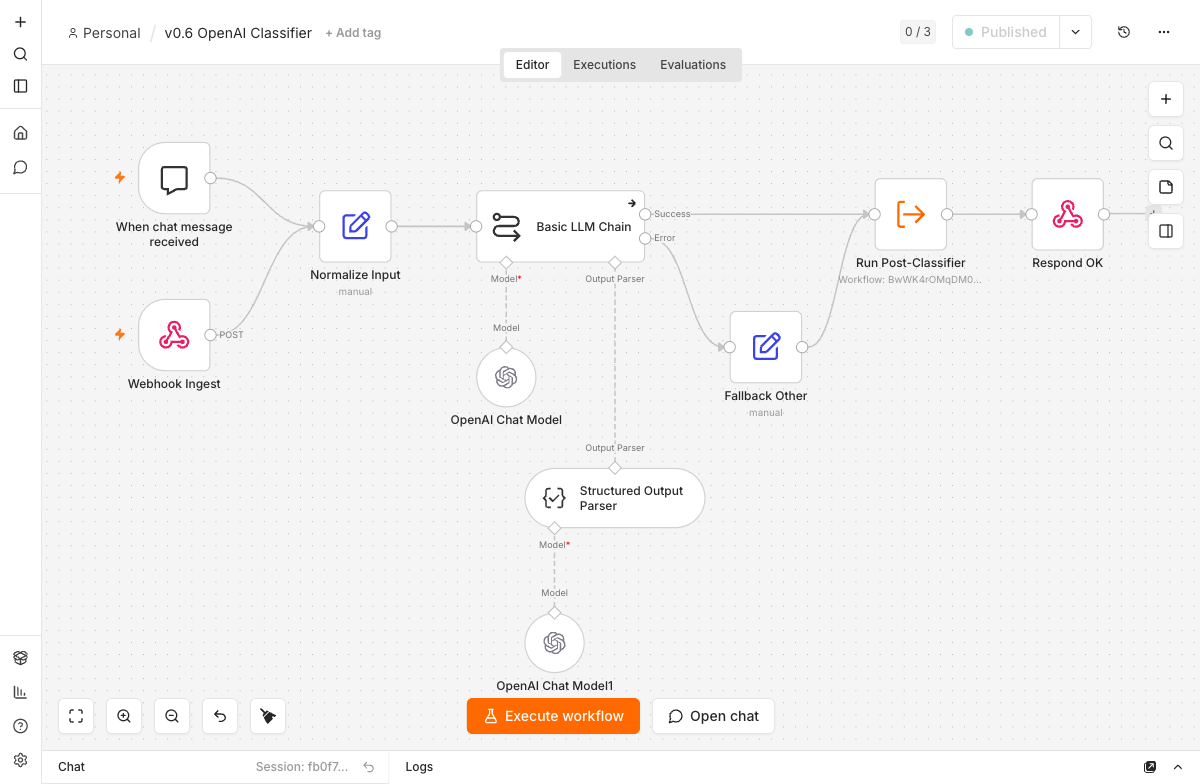
n8n ships several nodes for language models. The most prominent is the AI Agent node, designed for workflows with tools, memory, and multi-step reasoning. For a pure classification task it’s the wrong tool. We don’t need an agent that selects tools — we need a single model call whose response follows a fixed schema.
The first attempt using the AI Agent node with an attached Structured Output Parser ran straight into a wall. The parser reported The AI model returned an empty response, even though valid JSON was visible in the input panel. With Auto-Fix enabled, the response became Model output doesn't fit required format instead. A direct test against the model outside of n8n returned clean schema-compliant JSON every time. The model wasn’t the problem.
The explanation is in the n8n documentation itself:
“Structured output parsing is often not reliable when working with agents. If your workflow uses agents, n8n recommends using a separate LLM-chain to receive the data from the agent and parse it.”
For classification, that means: Basic LLM Chain instead of AI Agent. The chain makes exactly one model call, and the Structured Output Parser attaches directly to it. No agent loop that goes nowhere with smaller models. The agent remains the right tool when actual tool use or conversation memory is needed — not here.
Structured Output with JSON Schema
A classifier that returns free text is useless for downstream processing. We need a typed object that a Switch node can route on. The Structured Output Parser accepts a JSON Schema and forces the response into this shape:
{
"type": "object",
"properties": {
"category": {"type": "string", "enum": ["sap-basis", "sap-functional", "infrastruktur", "cloud", "security-pki", "sonstiges"]},
"confidence": {"type": "number", "minimum": 0, "maximum": 1},
"language": {"type": "string", "enum": ["de", "en"]},
"p1_suspected": {"type": "boolean"},
"p1_reason": {"type": "string"}
},
"required": ["category", "confidence", "language", "p1_suspected", "p1_reason"]
}
The system message describes the six categories with their typical terms and the rules for each field. confidence is the model’s self-assessment, p1_suspected flags suspected emergencies — more on that later. Auto-Fix mode appends a second model call when a schema violation occurs, to repair the broken response. This repair pass requires its own Chat Model sub-node, otherwise n8n throws A Model sub-node must be connected and enabled.
The OpenAI Chat Model node carries a toggle that’s easy to overlook when first pointing it at a local server: Use Responses API. When active, the node calls /v1/responses rather than /v1/chat/completions. Our local MLX server doesn’t know that endpoint and responds with a 404 that langchain translates into the misleading message MODEL_NOT_FOUND. Anyone who sees that will check the model name first — and look in the wrong place. The fix is one click: toggle off. Ollama does implement /v1/responses, so the toggle doesn’t matter there.
Two Local Models, No Cloud Key
Data sovereignty is a recurring theme in this series. A classifier that sends every ticket to a cloud API contradicts that. So the classification runs locally — with two different backends in parallel.
The first is Ollama with qwen2.5:7b, the reproducible path for readers. Ollama exposes an OpenAI-compatible endpoint; the n8n OpenAI Chat Model node speaks it directly. The credential gets http://host.docker.internal:11434/v1 as the base URL and any arbitrary API key, since Ollama doesn’t check one. host.docker.internal is necessary because n8n runs inside a container, where localhost refers to the container itself, not the host.
The second backend is our own Hummingbird-MLX server with Qwen3-8B-4bit. It exposes an Anthropic-compatible endpoint at /v1/messages, so we attach the Anthropic Chat Model node there. The node choice follows the endpoint coverage: the OpenAI node reaches Ollama and MLX, the Anthropic node reaches MLX and real Claude in the cloud. No single node covers all three worlds.
Ollama or your own Hummingbird-MLX gateway — the core point stands: the entire classifier runs without an API key. A local model replaces the cloud completely.
Starting Ollama and the Hummingbird-MLX server
Both model backends run on the host, not inside the n8n container. n8n reaches them via host.docker.internal (see above). It’s enough to start the backend whose Chat Model node the workflow actually uses.
Ollama (OpenAI-compatible, port 11434):
ollama serve &
ollama pull qwen2.5:7b
Check that the OpenAI-compatible endpoint responds:
curl -s http://localhost:11434/v1/models | jq .
The OpenAI credential in n8n gets http://host.docker.internal:11434/v1 as its base URL and any arbitrary API key.
Hummingbird-MLX gateway (Anthropic-compatible, port 8080):
The Hummingbird gateway from the series of the same name can be started two ways. Quick, straight from the project directory:
swift run gateway
Closer to production and with a shorter startup, via a release binary (details in Hummingbird, article 6):
swift build -c release
.build/release/gateway --host 0.0.0.0 --port 8080
Check that the gateway is running:
curl -s localhost:8080/healthz
curl -s localhost:8080/v1/models | jq .
The Anthropic credential in n8n points to http://host.docker.internal:8080. The Anthropic Chat Model node uses that to reach the /v1/messages endpoint.
Alongside the second backend, we make use of a more advanced pattern. The Auto-Fix repair pass doesn’t have to use the same model as the primary call. In the MLX workflow, the primary call goes to MLX Qwen3, while the repair pass uses Ollama Qwen2.5. Two local stacks cooperating. This makes sense when the repair model should be stronger than the primary model, or simply when a second provider provides redundancy.
Language Detection Is Not a Language Model’s Job
The schema includes a language field. The obvious approach would be to let the model estimate the language alongside the classification. A quick measurement shows why that’s a bad idea. A German ticket about an AKS cluster, full of English technical terms like Kubernetes, Pod, and IAM, gets classified as English by Qwen3. The smaller Ollama model, conversely, pulls English tickets toward German. Both models drift toward their dominant training language.
Language detection is a solved problem — deterministically. The franc-min library counts n-gram frequencies and is immune to individual technical terms. So we let the model fill the language field, but treat it as a diagnostic value only and overwrite it with the result from franc-min. A Code node after the chain handles this:
const { franc } = require('franc-min');
const txt = $json.pipelineInput || '';
const iso3 = franc(txt, { only: ['deu', 'eng'] });
const detected = iso3 === 'deu' ? 'de' : iso3 === 'eng' ? 'en' : 'unknown';
const c = $json.output;
return [{ json: {
category: c.category,
confidence: c.confidence,
language: detected,
language_llm: c.language,
language_match: c.language === detected,
p1_suspected: c.p1_suspected,
p1_reason: c.p1_reason,
route_pager: (c.p1_suspected === true) || ($json.priority === 'critical'),
} }];
The language_match field makes model drift measurable. Across the full evaluation it’s possible to quantify how often the model got the language wrong, without that affecting the end result.
External npm packages in a Code node are straightforward with self-hosting, but require a short detour. The package must be present in the Docker image, and the environment variable NODE_FUNCTION_ALLOW_EXTERNAL must enable it — both together. Anyone who tries npm install directly in the n8n installation directory will hit an error: n8n uses the pnpm catalog: protocol internally, which rejects regular npm calls in its directory. The clean solution is a separate package directory pointed to by NODE_PATH:
FROM n8nio/n8n:2.21.4
USER root
RUN mkdir -p /home/node/n8n-libs \
&& cd /home/node/n8n-libs \
&& npm init -y \
&& npm install franc-min \
&& chown -R node:node /home/node/n8n-libs
USER node
ENV NODE_PATH=/home/node/n8n-libs/node_modules
The corresponding docker-compose.yml replaces image: with build: . and enables the package:
services:
n8n:
build: . # local Dockerfile instead of registry image
environment:
NODE_FUNCTION_ALLOW_EXTERNAL: "franc-min"
volumes:
- n8n-data:/home/node/.n8n # credentials and workflows survive restarts
After an image change, docker compose up --build alone is not enough — the running container is not replaced in that case. The --force-recreate flag forces the swap. Targeting only the n8n service leaves Postgres untouched:
docker compose up --build --force-recreate n8n
Named volumes n8n-data and postgres-data survive container recreation. Credentials, workflows, and database contents are preserved.
Routing: Two Signals for the Alert
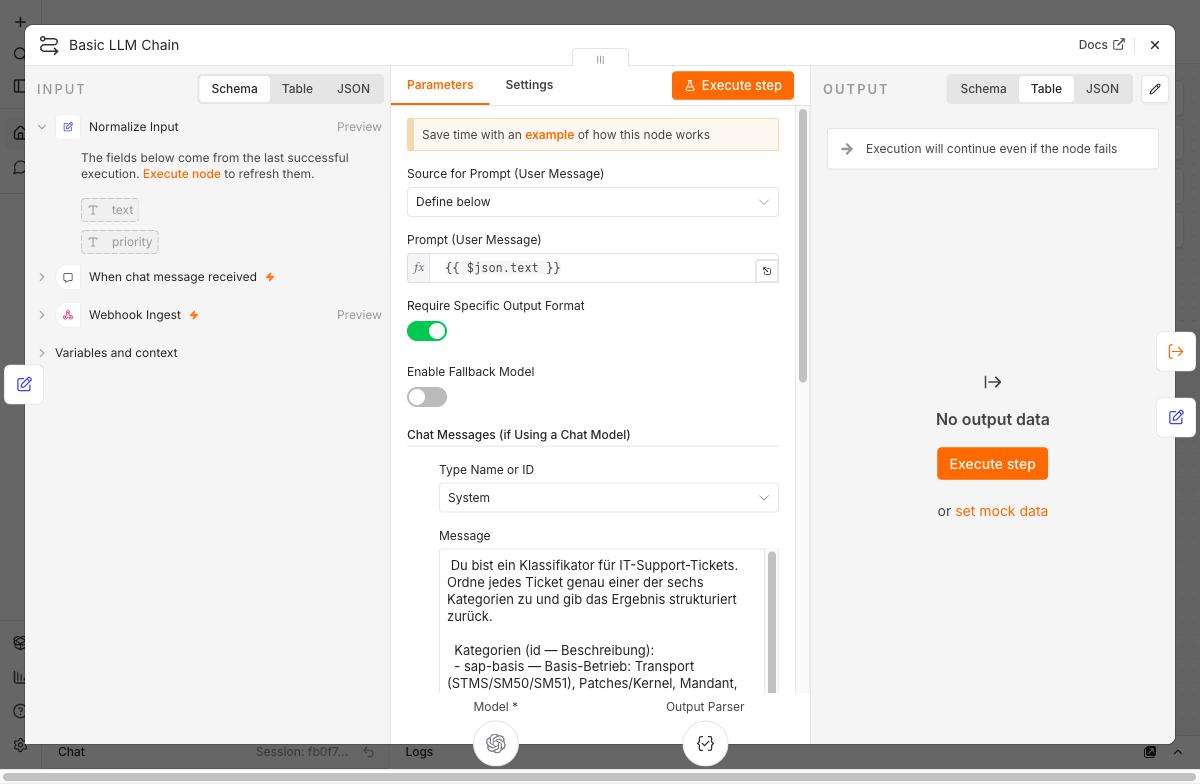
A classifier that only returns a category hasn’t shown its full value yet. The interesting question is which tickets need to wake someone up immediately. The ticketing system provides a priority field for that, set by the submitter. That field alone can’t be trusted. Some submitters flag every minor issue as critical; others report a production outage as medium priority because they don’t know the escalation procedure.
This is where the language model pays off. It reads the free text and can detect a silent emergency that the submitter’s priority doesn’t reveal. That’s what the p1_suspected field is for. The system message describes when it’s set: production outage, security incident, imminent data loss, business process standstill. The p1_reason field provides a brief explanation and makes the decision transparent — important for trust in an operational setting.
The routing rule combines both signals with an OR. An alert fires when the submitter has set critical or the model suspects a P1. The n8n Switch node supports only a single condition per rule, with no OR across multiple conditions. So we compute the combination in code, in the field route_pager, and the Switch checks only that one boolean. The advantage: the routing criterion is visible in the output and can be read directly during debugging.
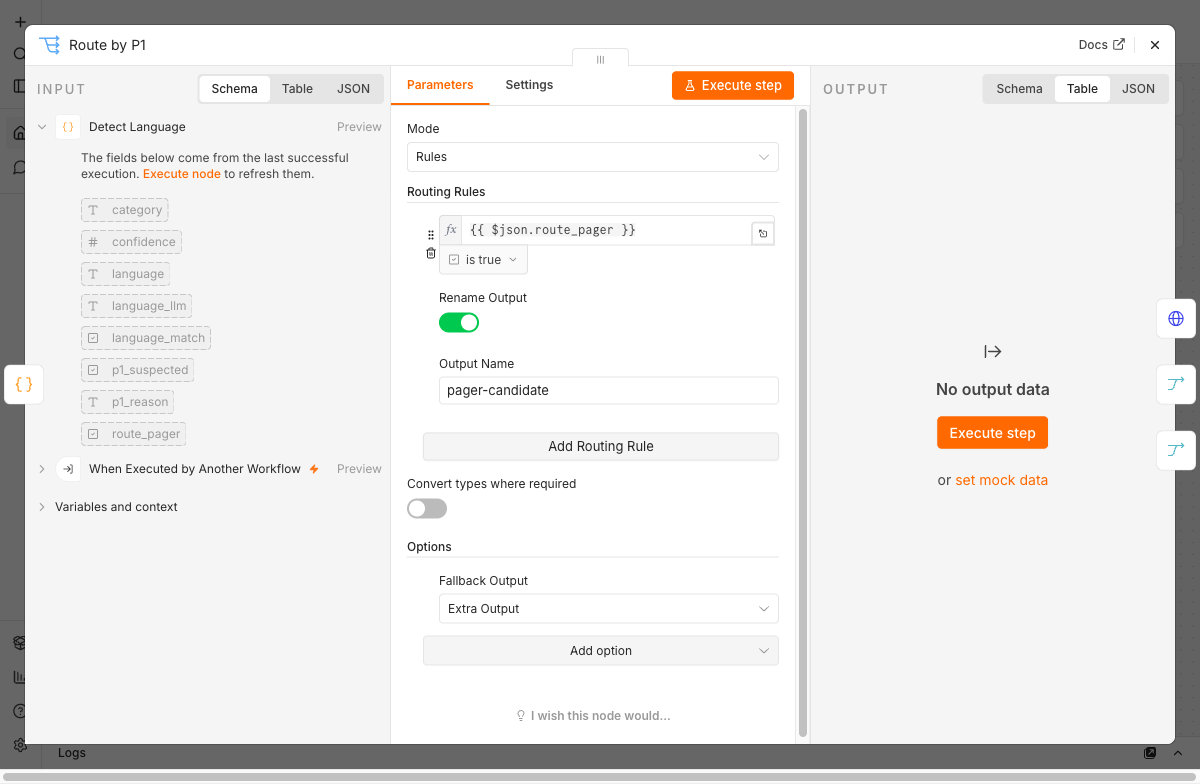
The alert itself is a PagerDuty call, in the demo against a test endpoint. The wiring matters. The alert must not replace the data item, because an HTTP node returns its own response and would overwrite the passing item. The solution is a fork. The pager branch splits into two strands. One fires the alert and ends there — a dead end. The other carries the classification data unmodified to the Merge node. The fallback branch reaches the Merge without the detour. After the Merge, all tickets continue together to the queue. A P1 ticket gets its alert in addition, but goes through the same processing as any other.
One Pipeline, Two Entry Points
Two workflows, one per model, differ in exactly one point: the Chat Model node. Language detection, routing, PagerDuty, and queue are identical. Maintaining the same logic in two places is an open invitation to divergence.
So the shared post-processing moves into its own sub-workflow, the Post-Classifier Pipeline. Both backend workflows call it via an Execute Workflow node and pass the classification object, the ticket text, and the priority. Article 5 used the same pattern for the rule-based sub-classifier. Switching backends is then a change to exactly one node, not two parallel copies.
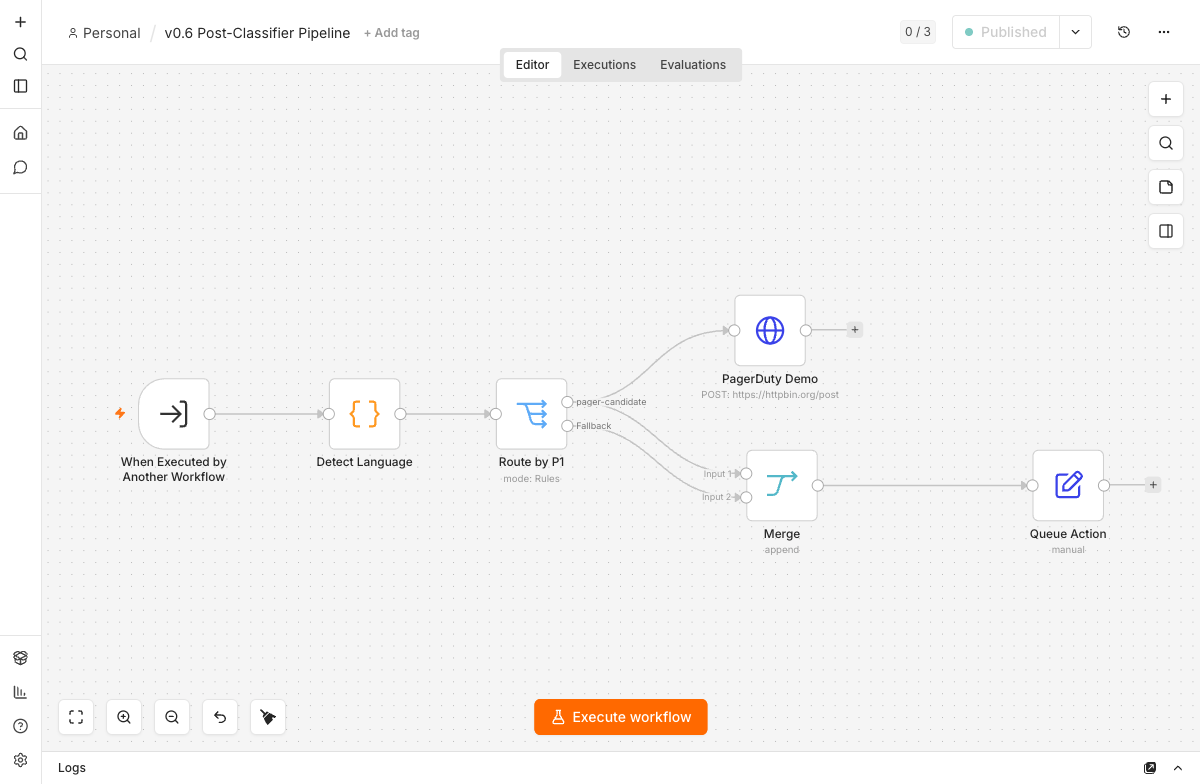
The entry point is shared between a Chat Trigger and a Webhook. The Chat Trigger is for quick iteration during development; the Webhook is the production entrance from Article 5, with header authentication. A Set node normalizes both sources to a common field before the chain takes over.
Evaluation and Interpreting the Results
One hundred tickets from the pinned dataset, through both workflows, against the known categories. The evaluate.py script posts each ticket to the webhook and builds a confusion matrix from the responses.
| Classifier | Category accuracy | Language accuracy | Time (100 tickets) |
|---|---|---|---|
| Ollama qwen2.5:7b | 97 % | 100 % | 1124 s |
| Hummingbird MLX Qwen3-8B | 98 % | 100 % | 1086 s |
| Rule-based (Article 4) | 97 % | — | < 1 s |
Language accuracy is 100 % for both models because franc-min determines it, not the model. On category accuracy, the MLX stack comes in slightly ahead and is marginally faster as well. Both models comfortably exceed the 80 % threshold anchored in the test suite.
The rule-based baseline from Article 4 also reaches 97 %. At first glance, a sobering result: all that effort for a language model, and the simple keyword rule keeps up. On second glance, that’s the actual lesson in this article.
The test dataset was generated by instructing a model to use at least one term from a fixed keyword list per category. Exactly those terms are what the rule-based classifier searches for. The tickets contain precisely the words the rule was designed to match. The benchmark gives the baseline a home-field advantage and systematically underestimates the gap to the language model. On real tickets — written by actual people without regard for keyword lists — the rule would fall behind noticeably, while the model would continue to recognize semantic proximity.
Anyone comparing rules against AI must not build the comparison dataset from the rule’s own keywords. Otherwise the benchmark is mainly measuring its own test data construction.
What the Models Don’t Handle Well
The errors distribute informatively. For the Ollama model, all three misclassifications fall in the cloud category — twice into sap-functional, once into infrastruktur. Cloud tickets often mix infrastructure and application vocabulary, and the smaller model picks the wrong dominant context. The MLX stack — already equipped with a larger model — spreads its errors more broadly, with one mistake each at the boundary between cloud and sonstiges, and between sonstiges and infrastruktur. The lead of Hummingbird-MLX over Ollama is real, but should be read with one caveat: Ollama now also provides MLX models for Apple Silicon hardware, and a direct comparison using identical model weights would tell a different story.
The pattern is understandable. The tickets that are hardest for the models are exactly the ones a human would only place correctly with context. A confidence value of 1.0 doesn’t mean the model is right — it means the model feels certain. Both values belong in the observation, not just the category.
The experience with language detection remains a useful reminder. A language model is not automatically the best tool for every language-adjacent task. For pure language detection, the deterministic n-gram counter beats the billion-parameter model — because it was built for exactly that task.
What’s Next
The workflow now classifies with a local language model, routes critical tickets to an alert, and runs without cloud dependency. What’s missing is operational robustness. What happens when the model server doesn’t respond, a run aborts mid-processing, or a new workflow version replaces an old one? Article 7 adds error handling, observability, and versioning.
← Article 5: Webhooks, HTTP, and Credentials — the Production Entrance