One Entry Point, Two Classifiers — Merging the AI Pipeline into the Live Path

Article 8 · Series: Getting Started with n8n
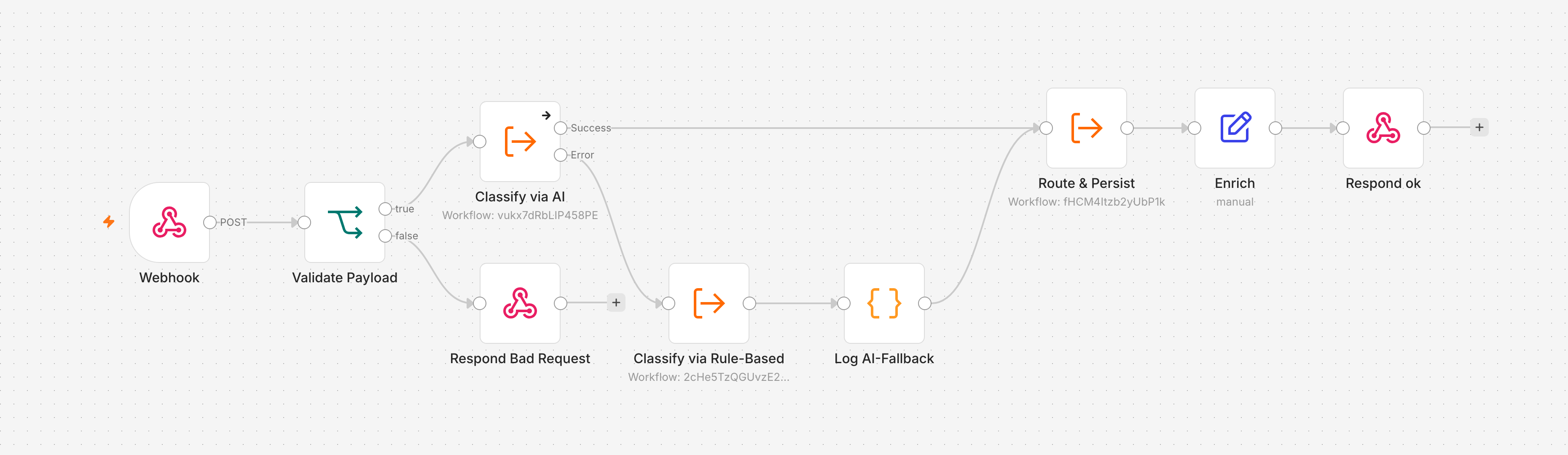
After Article 7 the workflow is production-ready, but split. There are two entry points: the rule-based /ticket-ingest from the early articles, which categorizes a ticket via keyword code and then ends, and the AI classification from Article 6, which queries a local language model through its own webhook and feeds into the routing pipeline. Two paths, two kinds of classification, and only the AI path reaches routing and persistence. This article merges them into the single pipeline that ADR 002 intended from the start: one entry point, the AI as the primary classification, the rule-based classifier as a fallback, one shared routing.
The code for this article is on Codeberg, tag v0.8: codeberg.org/rotecodefraktion/n8n-einstieg.
Classification as a swappable stage
The guiding idea behind the merge is a separation of responsibilities. The entry point accepts tickets, validates them, and passes them on. The routing decides, based on category and P1 suspicion, what happens to the ticket. Classification sits in between, and ideally it is a black box: it takes a normalized text and returns a structured result. Whether a language model, a keyword matcher, or later a set of several backends sits behind it must not concern the entry point or the routing.
n8n makes this separation tangible through sub-workflows. A workflow whose first node is an Execute Workflow Trigger defines input fields and return values and can be called from another workflow like a function. The merge relies on exactly this property: the entry point calls the classification as a sub-workflow instead of containing it inline. That makes the classification stage swappable without touching the entry point.
From keyword code to AI classification
The previous /ticket-ingest called a sub-workflow that determined the category through keyword matching. The rebuild replaces that call with an Execute Workflow node that calls the AI classification, the v0.8 OpenAI Classifier. The name carries the OpenAI heritage because the node type is lmChatOpenAi, but the backend is local. By default Ollama runs with qwen2.5:7b, the reproducible path from Article 6: an ollama pull qwen2.5:7b is enough, no self-built gateway required.
The credential deserves a closer look. The OpenAI Chat Model node speaks an OpenAI-compatible API, and which one is decided solely by the base URL in the credential. A credential “Ollama lokal” points to http://host.docker.internal:11434/v1, a second one “Hummingbird MLX” to the MLX gateway. The model field qwen2.5:7b is only a label; what actually answers depends on the credential. This swappability at the credential level is the precursor to the round-robin in Article 9. For the merge the rule is: one backend, Ollama, reproducible.
The call receives the normalized fields as inputs, id, subject, body, language, and returns an output object with category, confidence, language, p1_suspected and p1_reason. On the success path the entry point passes this output straight to the shared routing pipeline.
Why the internal fallback has to go
The AI classifier from Articles 6 and 7 had an On Error on the Basic LLM Chain set to Continue (using error output). When the model went down, the workflow did not abort but ran into an internal branch that silently categorized the ticket as sonstiges. On its own that made sense: the ticket flow should not break just because a model is temporarily gone.
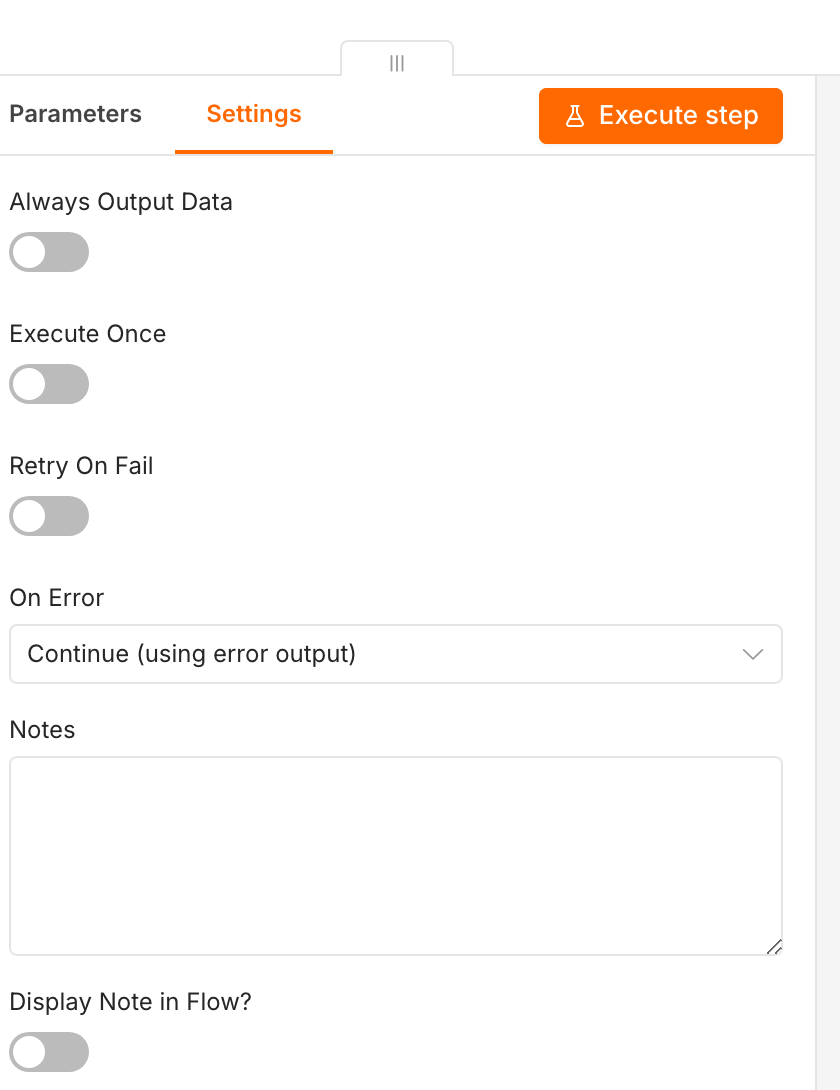
For the merge that very internal fallback is a problem. As long as the classifier catches its own failure, the Execute Workflow call never fails. The entry point always sees a success and can never switch to a fallback. The error handling therefore has to move out of the classifier and into the entry point. From now on the classifier fails for real when the model does not answer or returns invalid JSON, and the entry point decides what happens next.
Inside the entry point this looks as follows: the Execute Workflow node Classify via AI gets its On Error set to Continue (using error output). Its regular output leads to the success path, its error output into a second Execute Workflow node, Classify via Rule-Based, which calls the rule-based sub-classifier from Article 4. The architecture is now inverted: the classifier no longer masks its failure; the entry point catches it and switches to a second, independent classification.
The rule-based classifier is not a stopgap
It is tempting to dismiss the keyword classifier as a worse AI. That misses its purpose. It is a deterministic fallback with no external dependency. When the model is gone, a keyword-based categorization is better than none, and above all better than a silent sonstiges for every ticket. The rule-based path needs neither network nor model server, runs in milliseconds, and returns a traceable result. That is exactly why it stands as a deliberate second layer behind the model.
That this second layer is not theory became clear during testing. For one ticket qwen2.5:7b returned an essentially correct result, but phrased the reasoning as "p1_reason": "Produktivausfall (...)" with a straight double quote in the middle of the free text. That ended the JSON string too early, the Structured Output Parser failed, and the downstream Output Fixing Parser did not straighten it out either. So the AI call failed on a formatting detail of the model, not on an outage. The rule-based fallback caught exactly that. A small local model that occasionally produces invalid JSON is not an edge case but the normal mode of operation, and therefore the strongest argument for a deterministic second layer.
The lesson for the prompt: the free-text field p1_reason was given the explicit instruction to contain no quotation marks. After that the model phrased the reasoning with parentheses, and the JSON stayed parseable. Such hardening at the prompt is the price for structured output from small models.
One return schema for both paths
The third and most subtle trap lies in the data flow. The shared routing pipeline is itself a sub-workflow and expects defined inputs: an output object with category, confidence, language, p1_suspected, p1_reason, plus the pipelineInput for language detection and the priority. Its first code node reads $json.output.category. If there is no output, the pipeline aborts with Cannot read properties of undefined.
The AI classifier returns this output object on its own. The rule-based classifier does not: it returns a flat object with category, scores and match_count, without any output wrapper and without confidence or p1_suspected. If the fallback branch passed this flat result on unchanged, the pipeline would fall over at exactly this point, even though the fallback formally worked.
The fix sits in the fallback branch: a code node wraps the flat rule-based result into the same output shape the AI path delivers. This node is also the place where the degradation becomes observable, as begun in Article 7.
// Mode: Run Once for Each Item
console.log(JSON.stringify({
marker: 'n8n-ai-fallback',
backend: 'ollama',
ticketId: $json.id ?? $('Webhook').item.json.body?.id ?? null,
workflowName: $workflow.name,
reason: 'AI classifier failed, rule-based fallback',
timestamp: new Date().toISOString(),
}));
const r = $input.item.json;
return { json: { output: {
category: r.category ?? 'sonstiges',
confidence: 0,
language: r.language ?? 'unknown',
p1_suspected: false,
p1_reason: 'rule-based fallback',
} } };
The confidence: 0 is deliberate. It signals to the routing and to any later analysis that this result came from the fallback and not from the model. The marker n8n-ai-fallback, still in the internal classifier branch in Article 7, moves with this inversion to its logical place: into the entry point, where the decision “AI degraded, rule-based takes over” actually happens.
A pitfall from Article 7 that strikes again here
During testing a correction initially went nowhere, and the reason is the same as in Article 7: the save-versus-publish model from n8n 2.0. A change to a node’s code does not become live automatically. Production executions keep running against the last published version while the editor already shows the corrected draft. Anyone editing a code node has to publish explicitly (Shift + P), otherwise the old logic fires in production. With a fallback branch this surfaces especially late, because it only runs on failure. This separation is not a side detail; it is the most common cause of “but it looks right in the editor”.
End-to-end and fallback test
Two tests secure the merge. The first sends a valid ticket against the entry point and checks that the AI classifies and the pipeline routes:
curl -sk -X POST https://localhost/webhook/ticket-ingest \
-H "Content-Type: application/json" \
-H "X-Ingest-Token: <token>" \
-d '{"id":"E2E-001","subject":"SM50 work process restart",
"body":"All work processes in PRIV mode, users cannot log on.",
"priority":"high","language":"en"}'
The response comes back with HTTP 200 and a full result: category: sap-basis, confidence: 1, p1_suspected: true, routed to queue-sap-basis and reported to the PagerDuty demo endpoint. The AI path ran, the routing took hold.
The second test stops Ollama and sends the same pattern again:
# stop Ollama, then trigger again
curl -sk https://localhost/webhook/ticket-ingest -H "X-Ingest-Token: <token>" -d '{...}'
# marker on standard output
docker logs --since 1m docker-n8n-1 | grep n8n-ai-fallback
Now the Classify via AI call fails for real, the entry point switches to the rule-based classifier, the marker n8n-ai-fallback appears on standard output with the ticket ID, and the ticket is routed anyway, with confidence: 0 as the fallback signature. The webhook still answers with HTTP 200, and the entry point’s execution counts as success. Worth noting: the v0.7-error-handler from the previous article still fires on the AI outage, because the sub-workflow Classify via AI genuinely failed. The degradation thus stays visible over two channels, the error workflow and the fallback marker, while the ticket flow remains untouched.
What comes next
Classification is now a swappable stage with a deterministic fallback behind it. What is missing is real redundancy on the AI level itself: a second model backend that takes over before the rule-based emergency exit kicks in. In the next article one AI backend becomes a set of two, Ollama and the Hummingbird MLX gateway, distributed via round-robin and with real failover (Article 9). The rule-based classifier moves one layer back with that: from the first fallback to the last.