Two Models, One Entry Point — Round-Robin and Failover over Local AI Backends

Article 9 · Series: Getting Started with n8n
At the end of Article 8 the entry point has an AI classification with a rule-based fallback behind it. That catches a model outage, but coarsely: when the one backend fails, the keyword matcher classifies immediately, with confidence: 0. A tier in between is missing. This article adds it by turning one AI backend into two: a local Ollama model and the Hummingbird MLX gateway, distributed via round-robin in normal operation, with real failover onto each other on an outage. The rule-based classifier moves one layer back with that, from the first fallback to the last, kicking in only when both AI backends are down.
The code for this article is on Codeberg, tag v0.9: codeberg.org/rotecodefraktion/n8n-einstieg.
Graceful degradation is not failover
Article 7 made the silent model outage observable, Article 8 moved the rule-based fallback into the entry point. Both are graceful degradation: when the AI is gone, the ticket flow continues with a worse but working classification. Failover is something else. Failover means a second, equivalent backend takes over without loss of quality, and the emergency exit stays shut as long as any AI backend answers. The difference matters in operation: for a single gateway restart you do not want to collect every ticket in a keyword classification for an hour while a second model sits ready next door.
That takes two things: a second AI backend returning the same output schema, and a dispatcher that distributes the load and switches over on a failure.
The second backend speaks Anthropic, not OpenAI
The first backend is the v0.8 OpenAI Classifier from Article 8: an OpenAI Chat Model node running against qwen2.5:7b via the Ollama lokal credential. For the second one I duplicated that classifier and pointed it at the Hummingbird MLX gateway. Here lies the first surprise: the gateway speaks not the OpenAI but the Anthropic API. Both chat model nodes in the duplicate therefore had to switch from “OpenAI Chat Model” to “Anthropic Chat Model”, with an Anthropic credential whose base URL points at the gateway (http://host.docker.internal:8080). Which API is spoken is decided solely by the credential, not by the node name or the model field.
The second surprise is in the model. The gateway serves mlx-community/Qwen3-8B-4bit, and Qwen3 runs in thinking mode: it puts its reasoning as prose in front of the actual answer. Nice for a chat application, fatal for a structured output parser, because there is a paragraph of prose before the JSON. The fix is a /no_think at the very start of the system prompt. With it Qwen3 suppresses the reasoning block and returns clean JSON directly. Trying to achieve this via the API parameter chat_template_kwargs: {enable_thinking: false} fails because the gateway does not pass it through; the prompt prefix works reliably.
That is the real lesson of this tier: two backends are not two interchangeable boxes. qwen2.5 needs no /no_think, Qwen3 does. Anyone building redundancy across different models hardens each prompt against the quirks of its backend.
Round-robin via staticData
The dispatcher starts with the question of which backend sees a ticket first. Rather than hard-wiring it or leaving it to chance, a Code node distributes the load in turn. n8n provides $getWorkflowStaticData('global') for this, a small store that persists across runs per workflow. A counter in it, modulo two, determines the order:
// Mode: Run Once for Each Item
const s = $getWorkflowStaticData('global');
s.rr = (s.rr || 0) + 1;
const OLLAMA = 'vukx7dRbLIP458PE'; // v0.8 OpenAI Classifier
const MLX = 'FDCjcytGNeO3ODH6'; // v0.9 MLX Classifier
const order = (s.rr % 2 === 0) ? [OLLAMA, MLX] : [MLX, OLLAMA];
const b = $json.body;
return { json: {
id: b.id, subject: b.subject, body: b.body, language: b.language,
priority: b.priority ?? '',
primaryId: order[0], secondaryId: order[1],
primaryBackend: order[0] === OLLAMA ? 'ollama' : 'mlx',
secondaryBackend: order[1] === OLLAMA ? 'ollama' : 'mlx',
} };
The node passes on not only the normalized ticket fields but also primaryId and secondaryId, the two backend workflows in the order chosen for this run. The secondaryId is always the other backend than primaryId. A note on staticData: the store is persisted only for active, production runs; manual editor runs do not increment the counter. For load distribution in operation that is enough.
The failover cascade with a dynamic workflow ID
This is where the Article 8 decision to encapsulate classification as a sub-workflow pays off. The dispatcher does not call two hard-wired backends but calls the same Execute Workflow node type twice, its target workflow coming from an expression on the ticket.
The first Execute node, Classify via AI (primary), gets its workflow ID from {{ $json.primaryId }}, the second, Classify via AI (secondary), from {{ $json.secondaryId }}. Both are set to On Error: Continue (using error output). That yields the cascade:
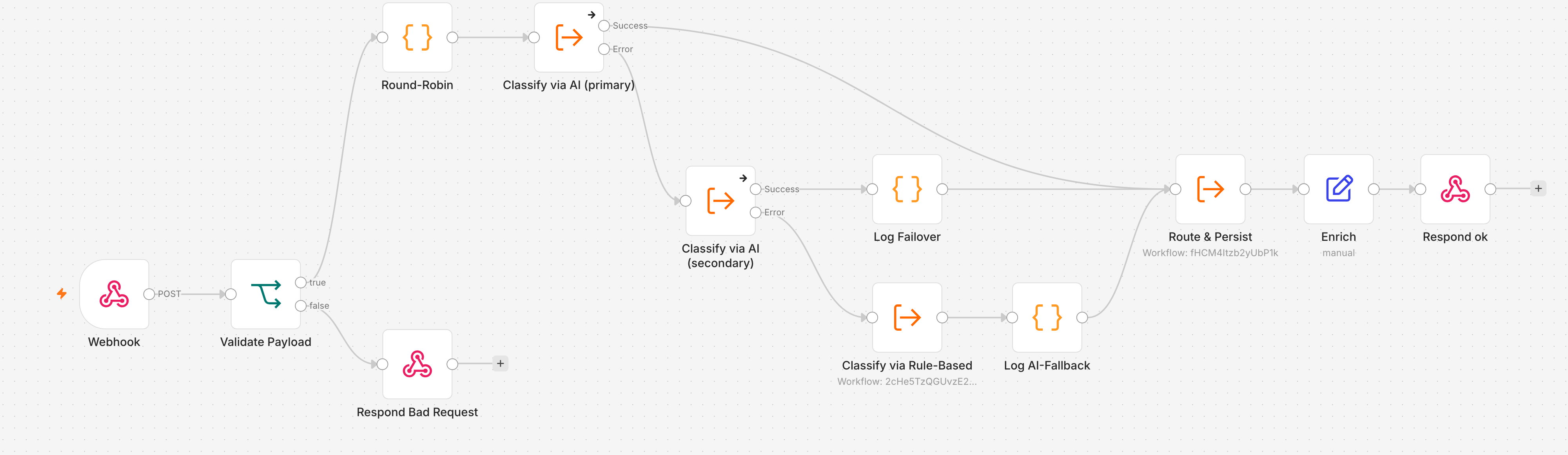
The primary call leads straight into the shared routing on success. If it fails, its error output runs into the secondary call, which addresses the other backend. Only if that also fails does the rule-based classifier from Article 4 kick in, followed by the marker and the routing. A detail when building: so that the Execute node’s input form shows the fields id, subject, body, language, you first pick a concrete workflow from the list, map the fields, and only then switch the source to “By ID” with the expression; the mapping is preserved.
The cascade reads the backend names for the markers back via $('Round-Robin').item.json. This paired-item reference carries through the Execute calls, even when the backend in between has failed.
Three tiers of observability
Two backends and one emergency exit yield three operating states, and each gets its own trace. In normal operation exactly one backend runs, there is nothing to report, no marker. On a single outage the second backend takes over, and that is an event you want to see. On the success path of the secondary call, which only runs after a primary failure, sits a Code node Log Failover:
// Mode: Run Once for Each Item
const rr = $('Round-Robin').item.json;
console.log(JSON.stringify({
marker: 'n8n-ai-failover',
failedBackend: rr.primaryBackend,
servedBackend: rr.secondaryBackend,
ticketId: rr.id ?? null,
workflowName: $workflow.name,
reason: 'primary AI backend failed, secondary took over',
timestamp: new Date().toISOString(),
}));
return $input.item;
The third state is the double outage. The Log AI-Fallback node from Article 8 stays, but instead of a hard-wired backend name it now writes both failed backends into the marker:
const rr = $('Round-Robin').item.json;
console.log(JSON.stringify({
marker: 'n8n-ai-fallback',
failedBackends: [rr.primaryBackend, rr.secondaryBackend],
ticketId: rr.id ?? $json.id ?? null,
workflowName: $workflow.name,
reason: 'both AI backends failed, rule-based fallback',
timestamp: new Date().toISOString(),
}));
// ... wrap the rule-based result into the output schema, confidence: 0
Via Alloy both markers land in Loki. n8n-ai-failover shows when which backend wobbled without the classification suffering, n8n-ai-fallback shows the rare case where both were gone. On top of that the global error workflow from Article 7 fires on every backend failure anyway, since the sub-workflow genuinely failed. A single outage is thus visible over two channels and still does not disturb the ticket flow.
Verification: round-robin, failover, double outage
Three tests secure the tier. The first sends several tickets with both backends running and reads from the executions which classifier ran:
| Ticket | Backend (execution) |
|---|---|
| 1 | MLX |
| 2 | Ollama |
| 3 | MLX |
| 4 | Ollama |
Clean alternation, one backend per run. Incidentally the response reveals the backend: qwen2.5 returns confidence: 1 for the production outage, Qwen3 returns 0.95.
The second test stops Ollama and sends again. Where MLX is primary it classifies directly, where Ollama is primary the call fails and MLX takes over. Every ticket still gets a real AI classification, the rule-based fallback stays untouched, and the failover marker appears in the log:
{"marker":"n8n-ai-failover","failedBackend":"ollama","servedBackend":"mlx","ticketId":"..."}
The third test stops both. Now both calls fail, the rule-based classifier kicks in, the ticket is routed with confidence: 0, HTTP 200, and the fallback marker carries both failed backends:
{"marker":"n8n-ai-fallback","failedBackends":["mlx","ollama"],"ticketId":"..."}
Transition to Article 10
The classification tier is now resilient: load distributed, single outage absorbed, emergency exit only on total failure. With that the AI side of the pipeline is complete. The next article leaves classification and turns to persistence, which until now has been just a demo fork: the SAP bridge over OData and HTTP, and where the SAP standard’s native AIF stays complementary (Article 10).
Second backend without the MLX gateway: a second Ollama model
Round-robin needs two backends, but not necessarily the Hummingbird MLX gateway. Anyone who does not want to build the Swift gateway uses a second Ollama model as the second backend. The only prerequisite is another pull:
ollama pull llama3.1:8b
Instead of the v0.9 MLX Classifier with the Anthropic node, the sub-workflow is then built with a second OpenAI Chat Model node, credential Ollama lokal, model llama3.1:8b. The /no_think is dropped because llama3.1 has no thinking mode; in exchange a look at the JSON formatting, which varies between models, pays off. The dispatcher logic stays identical: round-robin and failover do not care which two backends sit behind them, only that there are two and both return the same schema.